Prometheus
架构介绍
介绍
1.一套开源的系统监控报警框架。
Prometheus基于Golang编写,不存在任何的第三方依赖。由
SoundCloud开源监控告警解决方案。单一节点就可以存储百万的监控指标,每秒处理数十万的数据点。
简单的可扩展性,
Prometheus对于联邦集群的支持,可以让多个Prometheus实例产生一个逻辑集群,当单实例Prometheus Server处理的任务量过大时,通过使用功能分区(
sharding)+联邦集群(federation)可以对其进行扩展。开放性,使用
Prometheus的client library的输出格式不止支持Prometheus的格式化数据,也可以输出支持其它监控系统的格式化数据,比如
Graphite。
https://prometheus.io/docs/instrumenting/clientlibs/
优劣势
易管理性:
Prometheus核心部分只有一个单独的二进制文件,可直接在本地工作,不依赖于分布式存储。Nagios/zabbix: 需要有专业的人员进行安装,配置和管理,并且过程很复杂。业务数据相关性:
监控服务的运行状态,基于Prometheus丰富的Client库,用户可以轻松的在应用程序中添加对Prometheus的支持,从而让用户可以获取服务和应用内部真正的运行状态。https://prometheus.io/docs/instrumenting/clientlibs/
Nagios/zabbix:大部分的监控能力都是围绕系统的一些边缘性的问题,主要针对系统服务和资源的状态以及应用程序的可用性。
高效:单一
Prometheus可以处理数以百万的监控指标;每秒处理数十万的数据点。
易于伸缩:通过使用功能分区(sharing)+联邦集群(federation)可以对Prometheus进行扩展,形成一个逻辑集群;
Prometheus提供多种语言的客户端SDK,这些SDK可以快速让应用程序纳入到Prometheus的监控当中。良好的可视化:
Prometheus除了自带有Prometheus UI,Prometheus还提供了一个独立的基于Ruby On Rails的Dashboard解决方案Promdash。另外最新的
Grafana可视化工具也提供了完整的Proetheus支持,基于Prometheus提供的API还可以实现自己的监控可视化UI。由于数据采集可能会有丢失,所以 Prometheus 不适用对采集数据要 100% 准确的情形。
但如果用于记录时间序列数据,Prometheus 具有很大的查询优势,此外,Prometheus 适用于微服务的体系架构。
工作过程:
- Prometheus server定期从配置好
- 的jobs或者exporters中拉取metrics, 或者接收来自Pushgateway发送过来的metrics,或者从其它的Prometheus server中拉metrics。
- Prometheus server在本地存储收集到的metrics,并运行定义好的alerts.rules,记录新的时间序列或者向Alert manager推送警报。
- Alertmanager根据配置文件,对接收到的警报进行处理,发出告警。
- 在图形界面中,可视化采集数据。
server安装
安装 server
解压:
[root@node2 soft]# tar xf prometheus-2.17.2.linux-amd64.tar.gz -C /usr/local/
启动:
[root@node2 prometheus-2.17.2.linux-amd64]# ./prometheus --config.file=./prometheus.yml
验证:
[root@node2 ~]# lsof -i :9090
默认配置
global: 主要有四个属性
scrape_interval: 拉取 targets 的默认时间间隔。
scrape_timeout: 拉取一个 target 的超时时间。
evaluation_interval: 执行 rules 的时间间隔。
external_labels: 额外的属性,会添加到拉取的数据并存到数据库中。
数据浏览
查看所有metrics:
http://192.168.204.132:9090/metrics
图形查看:
http://192.168.204.132:9090/graph
Using the expression browser:
promhttp_metric_handler_requests_total:server所有请求
promhttp_metric_handler_requests_total{code="200"}
count(promhttp_metric_handler_requests_total)
Using the graphing interface:
rate(promhttp_metric_handler_requests_total{code="200"}[1m]):每秒请求率
Grafana图形展示:
http://192.168.204.132:3000
node_exporter安装
架构
负责数据的汇报,不同的Exporter负责不同的业务。
是一个独立运行的进程,对外暴露一个用于获取监控数据的HTTP服务。
其统一命名格式:xx_exporter。系统:node_exporter,MySQL:mysqld_exporter
下载&安装
地址:https://prometheus.io/download/#node_exporter
可以获取到所在主机大量的运行数据,典型的包括CPU、内存,磁盘、网络等等监控样本。
采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。
解压:
[root@node3 soft]# tar xf node_exporter-0.18.1.linux-amd64.tar.gz -C /usr/local/
启动:
[root@node3 node_exporter-0.18.1.linux-amd64]# ./node_exporter
验证:
[root@node3 ~]# lsof -i:9100
数据查看
http://192.168.204.133:9100/metrics
其他指标:
node_boot_time:系统启动时间
node_cpu:系统CPU使用量
node_disk*:磁盘IO
node_filesystem*:文件系统用量
node_load1:系统负载
node_memeory*:内存使用量
node_network*:网络带宽
node_time:当前系统时间
go_*:node exporter中go相关指标
process_*:node exporter自身进程相关运行指标
Server端配置
添加静态配置:发现node3节点
[root@node2 prometheus-2.17.2.linux-amd64]# vim prometheus.yml
- job_name: 'node'
static_configs:
- targets: ['192.168.204.133:9100']
重启server:
[root@node2 prometheus-2.17.2.linux-amd64]# ./prometheus --config.file=./prometheus.yml
数据浏览:
http://192.168.204.132:9090/graph
测试metric:node_load1
Grafana数据展示
地址:https://grafana.com/grafana/dashboards?direction=asc&orderBy=name
其他
https://prometheus.io/docs/instrumenting/exporters/#exporters-and-integrations
用户自定义:
除了直接使用社区提供的Exporter程序以外,用户还可以基于Prometheus提供的Client Library创建自己的Exporter程序,目前Promthues社区官方提供了对以下编程语言的支持:Go、Java/Scala、Python、Ruby。
同时还有第三方实现的如:Bash、C++、Common Lisp、Erlang,、Haskeel、Lua、Node.js、PHP、Rust等。
mysqld_exporter安装
架构
负责数据的汇报,不同的Exporter负责不同的业务。
是一个独立运行的进程,对外暴露一个用于获取监控数据的HTTP服务。
其统一命名格式:xx_exporter。系统:node_exporter,MySQL:mysqld_exporter
下载&安装
地址:https://prometheus.io/download/#mysqld_exporter
可以获取到所在MySQL大量的运行数据,典型的包括连接数、QPS、慢SQL等等监控样本。
采用Golang编写,并且不存在任何的第三方依赖,只需要下载,解压即可运行。
mysqld_exporter Node3节点MySQL 8.0建立账户:
mysql> CREATE USER 'exporter'@'localhost' IDENTIFIED BY 'Exporter123%';
mysql> GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'localhost';
解压mysqld_exporter:
[root@node3 soft]# tar xf mysqld_exporter-0.12.1.linux-amd64.tar.gz -C /usr/local
配置mysqld_exporter:
[root@node3 mysqld_exporter-0.12.1.linux-amd64]# more .my.cnf
[client]
user=exporter
password=Exporter123%
启动:
[root@node3 mysqld_exporter-0.12.1.linux-amd64]# ./mysqld_exporter --config.my-cnf=".my.cnf"
数据查看
Server端配置
添加静态配置:发现node3节点
[root@node2 prometheus-2.17.2.linux-amd64]# vim prometheus.yml
- job_name: 'mysqld'
static_configs:
- targets: ['192.168.204.133:9104']
重启server:
[root@node2 prometheus-2.17.2.linux-amd64]# ./prometheus --config.file=./prometheus.yml
数据浏览:
http://192.168.204.132:9090/graph
测试metric:mysql_global_status_threads_running
Grafana数据展示
pushgateway
架构
prometheus还是采用pull方式来采集pushgateway的数据,采集端通过push方式把数据push给pushgateway,来完成数据的上报。
主要解决:
1. prometheus无法直接连接采集节点。
2. 采集节点执行太快,prometheus可能拉取不及时。
下载、安装、启动
地址:https://prometheus.io/download/#pushgateway
安装:
[root@node2 soft]# tar xf pushgateway-1.2.0.linux-amd64.tar.gz -C /usr/local/
启动pushgateway:
[root@node2 pushgateway-1.2.0.linux-amd64]# ./pushgateway
自定义采集端
[root@node2 pushgateway-1.2.0.linux-amd64]# vim push_memory.sh
#!/bin/bash
# desc push memory info
total_memory=$(free |awk '/Mem/{print $2}')
used_memory=$(free |awk '/Mem/{print $3}')
job_name="custom_memory"
instance_name="192.168.204.132"
cat <Pushgateway查看
Prometheus集成pushgateway
[root@node2 prometheus-2.17.2.linux-amd64]# vim prometheus.yml
- job_name: "pushgateway"
honor_labels: true #使用采集端自定义标签
static configs :
- targets:["192.168.204.132:9091"]
重启prometheus server:
[root@node2 prometheus-2.17.2.linux-amd64]# ./prometheus --config.file=./prometheus.yml
自定义exporter
需求:添加Logical_CPU_core_total(逻辑cpu个数)
编写脚本:
[root@node3 node_exporter-0.18.1.linux-amd64]# mkdir key
[root@node3 node_exporter-0.18.1.linux-amd64]# cd key/
[root@node3 key]# vim key_runner
#! /bin/bash
echo Logical_CPU_core_total `cat /proc/cpuinfo| grep "processor"| wc -l`
运行:
[root@node3 key]# sh key_runner > key.prom
启动node_exporter:
[root@node3 node_exporter-0.18.1.linux-amd64]# ./node_exporter --collector.textfile.directory=/usr/local/node_exporter-0.18.1.linux-amd64/key/
PromQL基本概念
PromQL (Prometheus Query Language) 是 Prometheus 自己开发的数据查询 DSL 语言。
数据解读 (node3节点):
# HELP node_load1 1m load average.
# TYPE node_load1 gauge
node_load1 0.05
# HELP node_load15 15m load average.
# TYPE node_load15 gauge
node_load15 0.05
在time-series中的每一个点称为一个样本(sample),样本由以下三部分组成:
指标(metric):监控项的名称;
时间戳(timestamp):一个精确到毫秒的时间戳;
样本值(value): 一个float64的浮点型。
指标和标签
在形式上,所有的指标(Metric)都通过如下格式标示:
{ Metric类型-四种
Counter(计数器类型)
Counter类型的指标的工作方式和计数器一样,只增不减(除非系统发生了重置)。Counter一般用于累计值,例如记录请求次数、任务完成数、错误发生次数。
例如:node_network_receive_bytes_total{device=”ens33”} 2.873766021e+09Gauge(仪表盘类型)
Gauge是可增可减的指标类,可以用于反应当前应用的状态。比如在监控主机时,主机当前的内容大小(node_memory_MemFree),可用内存大小(node_memory_MemAvailable)。或者时容器当前的cpu使用率,内存使用率。
例如:node_load1 0.05Histogram(直方图类型)
主要用于表示一段时间范围内对数据进行采样(通常是请求持续时间或响应大小),并能够对其指定区间以及总数进行统计,通常它采集的数据展示为直方图。
例如:# TYPE prometheus_tsdb_compaction_chunk_range_seconds histogramSummary(摘要类型)
Summary类型和Histogram类型相似,主要用于表示一段时间内数据采样结果(通常时请求持续时间或响应大小),它直接存储了quantile(分位数)数据,而不是根据统计区间计算出来的。
例如:# TYPE go_gc_duration_seconds summary
Histogram与Summary存在价值
一般情况下人们都倾向于使用某些量化指标的平均值,例如CPU的平均使用率、页面的平均响应时间。
我们以系统API调用的平均响应时间为例:如果大多数API请求都维持在100ms的响应时间范围内,
而个别请求的响应时间需要5s,那么就会导致某些WEB页面的响应时间落到中位数的情况,而这种现象被称为长尾问题。
为了区分是平均的慢还是长尾的慢,最简单的方式就是按照请求延迟的范围进行分组。
例如,统计延迟在010ms之间的请求数有多少,而1020ms之间的请求数又有多少。通过这种方式可以快速分析系统慢的原因。Histogram和Summary都是为了能够解决这样问题的存在,
通过Histogram和Summary类型的监控指标,我们可以快速了解监控样本的分布情况。
Histogram与Summary联系
Histogram转换Summary:通过histogram_quantile()函数计算出其值的分位数。
例如: histogram_quantile(0.5, prometheus_tsdb_compaction_chunk_range_seconds_bucket)
Histogram通过histogram_quantile函数是在服务器端计算的分位数,而Sumamry的分位数则是直接在客户端计算完成。
因此对于分位数的计算而言,Summary在通过PromQL进行查询时有更好的性能表现,而Histogram则会消耗更多的资源。
反之对于客户端而言Histogram消耗的资源更少。
在选择这两种方式时用户应该按照自己的实际场景进行选择。
PromQL基本查询
查询时间序列
例如:prometheus_http_requests_total
prometheus_http_requests_total{handler="/metrics"}
{code="200"}
完全匹配:=和!=两种:
label=value
label!=value
正则匹配:~和~!两种,多个用|分隔
label=~regx
label!=~regx
如:prometheus_http_requests_total{handler=~"/metrics|/api/v1/query_range"}
范围查询
prometheus_http_requests_total{handler="/metrics"}[1m]
其他单位:
s - 秒
m - 分钟
h - 小时
d - 天
w - 周
y - 年
时间位移:prometheus_http_requests_total{handler="/metrics"}[1m] offset 1d
聚合查询
求和:
count(prometheus_http_requests_total) -- 瞬时数据
sum(prometheus_http_requests_total)
平均值:
avg(prometheus_http_requests_total) by (code)
平均增长:
increase(prometheus_http_requests_total{handler="/metrics"}[1m])
平均增长速率:长尾问题irate
rate(prometheus_http_requests_total{handler="/metrics"}[1m])
长尾问题:irate解决
标量和瞬时数据
标量:纯数值,没有时序
10
瞬时数据:有时序
count(prometheus_http_requests_total)
转换:
scalar(count(prometheus_http_requests_total))
PromQL操作符
数学运算
按MB展示:
node_memory_MemFree_bytes / 1024 / 1024
相加:
node_disk_written_bytes_total + node_disk_read_bytes_total
工作模式:依次找到与左边向量元素匹配(标签完全一致)的右边向量元素进行运算,如果没找到匹配元素,则直接丢弃。
其他运算符:
+ (加法)
- (减法)
* (乘法)
/ (除法)
% (求余)
^ (幂运算)
布尔/集合运算
布尔操作:0/1
用处:
prometheus_http_requests_total{handler=”/metrics”} > bool 1000集合:
and (并且)
or (或者)
unless (排除)
vector1 and vector2 会产生一个由vector1的元素组成的新的向量。该向量包含vector1中完全匹配vector2中的元素组成。(1,2,3/1,2,3)
vector1 or vector2 会产生一个新的向量,该向量包含vector1中所有的样本数据,以及vector2中没有与vector1匹配到的样本数据。(1,2,3/3,4)
vector1 unless vector2 会产生一个新的向量,新向量中的元素由vector1中没有与vector2匹配的元素组成。(1,2,3/3,4)
注意:默认与右向量中的所有元素进行匹配
匹配模式
典型两种:
一对一(one-to-one), 多对一(many-to-one)或一对多(one-to-many)。一对一匹配: ignoreing匹配时忽略某些便签。而on匹配限定在某些便签之内。
prometheus_http_requests_total{code=”200”,handler=”/metrics”,instance=”localhost:9090”,job=”prometheus”} / ignoring(handler)
promhttp_metric_handler_requests_total{code=”200”,instance=”localhost:9090”,job=”prometheus”}多对一: group_left或者group_right来确定哪一个向量具有更高的基数(充当“多”的角色)。
prometheus_http_requests_total{code=”200”} / ignoring(handler) group_left promhttp_metric_handler_requests_total{code=”200”,instance=”localhost:9090”,job=”prometheus”}
PromQL聚合操作
内置聚合运算
sum:
sum(prometheus_http_requests_total)
without:移除标签
by:保留标签
其他:
sum (求和)
min (最小值)
max (最大值)
avg (平均值)
stddev (标准差)
stdvar (标准差异)
count (计数)
count_values (对value进行计数)
bottomk (后n条时序)
topk (前n条时序)
quantile (分布统计)
count_values:统计每一个样本出现的次数
count_values("cishu", prometheus_http_requests_total)
quantile:计算分位数quantile(φ, express)其中0 ≤ φ ≤ 1
quantile(0.9, prometheus_http_requests_total)
增长率-counter类型
增长量:increase(v range-vector)
increase(prometheus_http_requests_total{handler=”/metrics”}[1m])增长率:rate(v range-vector)
increase(prometheus_http_requests_total{handler=”/metrics”}[1m]) / 60
rate(prometheus_http_requests_total{handler=“/metrics”}[1m]) – 长尾问题
irate(prometheus_http_requests_total{handler=“/metrics”}[1m]) – 瞬时增长率
– irate函数是通过区间向量中最后两个样本数据来计算区间向量的增长速率。这种方式可以避免在时间窗口范围内的“长尾问题”,并且体现出更好的灵敏度,通过irate函数绘制的图标能够更好的反应样本数据的瞬时变化状态。
– irate函数相比于rate函数提供了更高的灵敏度,不过当需要分析长期趋势或者在告警规则中,irate的这种灵敏度反而容器造成干扰。因此在长期趋势分析或者告警中更推荐使用rate函数。
预测-gauge类型
在告警中,如果业务是线性增长,那么告警可以起到作用。告警出现,相关人员进行处理。
比如监控文件系统剩余情况,但是有可能某些情况增长不是线性的,当你设置<10GB告警,有可能突然就满了,造成系统不可用。预测时间序列v在t秒后的值:predict_linear(v range-vector, t scalar)
predict_linear(node_memory_Active_file_bytes[6h], 10*3600) / 1024/1024
– 基于简单线性回归模型
分位数-Histogram/summary类型
Histogram和Summary用于体现数据分布情况。
TYPE prometheus_tsdb_compaction_chunk_size_bytes histogram
TYPE go_gc_duration_seconds summary转换Histogram –> Summary:
histogram_quantile(0.5, prometheus_tsdb_compaction_chunk_size_bytes_bucket)区别:
Summary是直接在客户端计算了数据分布的分位数情况。
histogram_quantile函数是在服务器端计算的分位数。
动态标签替换
up
label_replace(v instant-vector, dst_label string, replacement string, src_label string, regex string)
label_replace(up, "ljp", "$1", "instance", "(.*):.*")
label_join(v instant-vector, dst_label string, separator string, src_label_1 string, src_label_2 string, ...)
label_join(up, "ljp", "-----", "instance", "job")
PromQL HTTP查询
固定查询
Prometheus提供HTTP API接口:/api/v1
[root@node2 ~]# curl 'http://localhost:9090/api/v1/query?query=up' |python -m json.tool
更多参数
query=: Prometheus expression query string.
time=: Evaluation timestamp. Optional.
timeout=: Evaluation timeout. Optional. Defaults to and is capped by the value of the -query.timeout flag.
[root@node2 ~]# curl 'http://localhost:9090/api/v1/query?query=up&time=1588411186'|python -m json.tool
范围查询
接口:/api/v1/query_range
query=: Prometheus expression query string.
start=: Start timestamp.
end=: End timestamp.
step=: Query resolution step width in duration format or float number of seconds.
timeout=: Evaluation timeout. Optional. Defaults to and is capped by the value of the -query.timeout flag.
[root@node2 ~]# curl 'http://localhost:9090/api/v1/query_range?query=up&start=2020-05-02T09:10:30.781Z&end=2020-05-02T09:11:30.781Z&step=15s'| python -m json.tool
资料
地址:https://prometheus.io/docs/prometheus/latest/querying/api/
告警规则设置
Prometheus检测阈值,Alertmanager进一步处理(分组、抑制、静默等),最后发给接收端。
规则设置(阈值)
1. 指定规则文件
[root@node2 prometheus-2.17.2.linux-amd64]# vim prometheus.yml
rule_file:
- "alert_rules.yaml"
# - "second_rules.yaml"
2. 配置规则
[root@node2 prometheus-2.17.2.linux-amd64]# vim alert_rules.yml
groups:
- name: os_monitor
rules:
- alert: 系统告警1
expr: up == 0
# for: 2m
labels:
environment: product
annotations:
Alert_type: 系统告警
Server: '{{$labels.instance}}'
explain: "我还是曾经那个少年,。。。系统挂了:{{ $value }}"
- alert: 系统告警2
expr: node_load15 >= 0.01
for: 2m
labels:
environment: product
annotations:
Alert_type: 系统告警
Server: '{{$labels.instance}}'
explain: "当前CPU负载:{{ $value }}"
告警查看
- Web(实时告警):http://192.168.204.132:9090/alerts(rules)
- Metric(历史告警):ALERTS
关联alertmanager
Email告警
Prometheus检测阈值,Alertmanager进一步处理(分组、抑制、静默等),最后发给接收端。
alertmanager安装
软件地址:
https://prometheus.io/download/#alertmanager
安装:
[root@node2 soft]# tar xf alertmanager-0.20.0.linux-amd64.tar.gz -C /usr/local/
目录结构:
[root@node2 soft]# cd /usr/local/alertmanager-0.20.0.linux-amd64/
[root@node2 alertmanager-0.20.0.linux-amd64]# ll
total 48292
-rwxr-xr-x 1 3434 3434 26971621 Dec 11 22:13 alertmanager (服务)
-rw-r--r-- 1 3434 3434 380 Dec 11 22:51 alertmanager.yml (配置文件)
-rwxr-xr-x 1 3434 3434 22458246 Dec 11 22:14 amtool (检测工具)
-rw-r--r-- 1 3434 3434 11357 Dec 11 22:51 LICENSE
-rw-r--r-- 1 3434 3434 457 Dec 11 22:51 NOTICE
alertmanager配置(邮件告警)
# 全局配置,可以设置发送账户信息
global:
# 路由,根据标签告警发给谁
route:
# 接受端,设置接收端用户信息
receivers:
- ...
# 抑制规则,可以屏蔽告警
inhibit_rules:
[ - ... ]
# 模板,生成最终告警页面格式
templates:
[ - ... ]
# vim alertmanager.yml
global:
smtp_from: 'lijinpeng@xx.com.cn'
smtp_smarthost: 'mail.xx.com.cn:25'
smtp_hello: 'xx.com.cn'
smtp_auth_username: 'lijinpeng@xx.com.cn'
smtp_auth_password: 'xxxxxx'
smtp_require_tls: false
resolve_timeout: 5m
route:
receiver: 'email'
group_by: [...]
group_wait: 5s
group_interval: 5s
repeat_interval: 5m
receivers:
- name: 'email'
email_configs:
- to: 'lijinpeng@xx.com.cn'
send_resolved: true
Prometheus关联alertmanager
Prometheus负责产生告警,而Alertmanager负责告警产生后的后续处理。因此Alertmanager部署完成后,
需要在Prometheus中设置Alertmanager相关的信息。
配置prometheus:
[root@node2 prometheus-2.17.2.linux-amd64]# vim prometheus.yml# Alertmanager configuration alerting: alertmanagers: - static_configs: - targets: - localhost:9093重启prometheus:
[root@node2 prometheus-2.17.2.linux-amd64]# ./prometheus –config.file=./prometheus.yml &
route路由详解
分组机制
作用场景:
将告警信息合并成一个通知。由于系统宕机可能导致大量的告警被同时触发,这时就利用分组机制,将所有告警合并成一个。
Route路由特性
用来设置报警的分发策略,它是一个基于标签匹配规则的树状结构,按照深度优先从左向右的顺序进行匹配。
每一个告警都会从配置中的顶级路由(route)进入路由树,根据标签匹配规则进入到不同的子路由,并且根据子路由设置的接收器发送告警。如果未设置,将从父节点继承。
系统告警发给系统管理员、数据库告警发给数据库管理员:
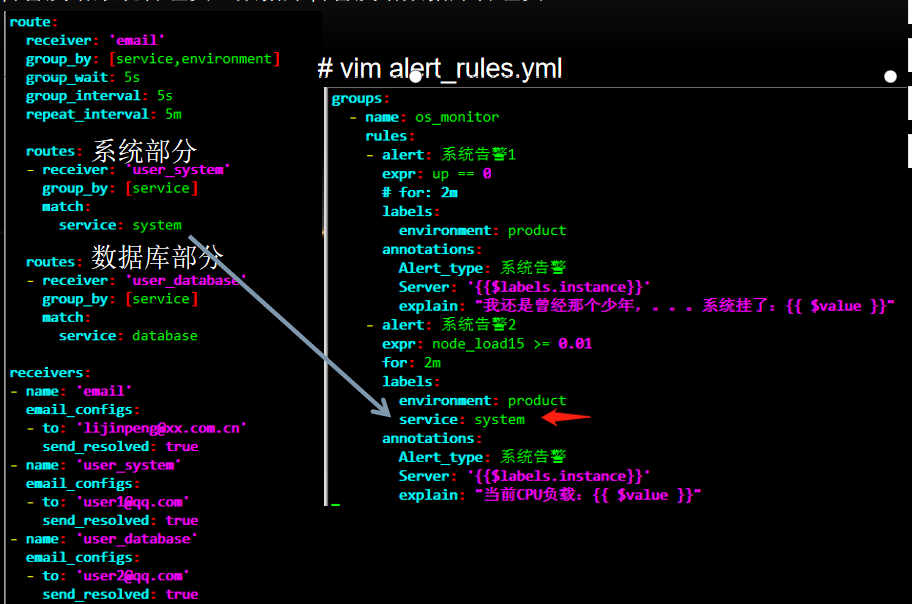
其他参数
match、match_re
continue:
false 告警在匹配到第一个子节点之后就直接发送。
true 报警则会继续进行后续子节点的匹配。
抑制规则inhibit与临时静默
屏蔽告警
两种:
抑制inhibit:根据配置规则自动屏蔽告警。
临时静默:web上手动屏蔽告警。
抑制规则
作用场景:
Alertmanager的抑制机制可以避免当某种问题告警产生之后用户接收到大量由此问题导致的一系列的其它告警通知。
例如当集群不可用时,用户可能只希望接收到一条告警(不是一组),目的是告诉我们这时候是集群出现了问题,而不要再发大量其他告警(如集群中的应用异常、中间件服务异常的告警通知了)
注意,与分组不同,分组是将多个告警合并成一个发送(根据标签,一个邮件告警中包含10个告警信息)
抑制,发一个告警(邮件中只有一个告警信息)可以是不同标签
优势,间接的帮你定位了问题根源。
需求:
两个告警,一个cpu负载,一个gc相关。假设cpu告警了,gc就不报警了。
Prometheus server端增加gc告警规则:
[root@node2 prometheus-2.17.2.linux-amd64]# vim alert_rules.yml
重启prometheus:
[root@node2 prometheus-2.17.2.linux-amd64]# ./prometheus –config.file=./prometheus.yml &

Alertmanager增加抑制策略:
[root@node2 alertmanager-0.20.0.linux-amd64]# vim alertmanager.yml
重启alertmanager:
[root@node2 alertmanager-0.20.0.linux-amd64]# ./alertmanager –config.file=alertmanager.yml

钉钉告警
安装go环境
软件获取:https://gomirrors.org/
安装:
[root@node2 soft]# tar xf go1.14.2.linux-amd64.tar.gz -C /usr/local/
设置环境变量:
[root@node2 local]# vim /etc/profile
export GOROOT=/usr/local/go #设置为go安装的路径
export GOPATH=/u01/soft/gocode #默认安装包的路径
export PATH=$PATH:$GOROOT/bin:$GOPATH/bin
golangci-lint安装:
[root@node2 ~]# mkdir -p /u01/soft/gocode
[root@node2 gocode]# curl -sSfL https://raw.githubusercontent.com/golangci/golangci-lint/master/install.sh | sh -s v1.26.0 #会将golangci-lint下载到/u01/soft/gocode/bin
[root@node2 bin]# chmod a+x golangci-lint # 授权
安装webhook-dingding
软件获取:https://github.com/timonwong/prometheus-webhook-dingtalk
下载:
[root@node2 soft]# mkdir -p /u01/soft/gocode/src/github.com/timonwong/
[root@node2 soft]# cd /u01/soft/gocode/src/github.com/timonwong/
[root@node2 timonwong]# git clone https://github.com/timonwong/prometheus-webhook-dingtalk.git
开始编译:
[root@node2 timonwong]# cd prometheus-webhook-dingtalk/
[root@node2 prometheus-webhook-dingtalk-master]# make
-- 看我的日志make.txt
结果:
[root@node2 prometheus-webhook-dingtalk]# ll prometheus-webhook-dingtalk
-rwxr-xr-x 1 root root 15684553 May 9 20:49 prometheus-webhook-dingtalk
申请钉钉token:
https://oapi.dingtalk.com/robot/send?access_token=xxxxxxx
启动dingding-webhook
启动:
[root@node2 prometheus-webhook-dingtalk]# ./prometheus-webhook-dingtalk --ding.profile="webhook1=https://oapi.dingtalk.com/robot/send?access_token=xxxxxxx“
验证:
[root@node2 prometheus-webhook-dingtalk]# lsof -i:8060
COMMAND PID USER FD TYPE DEVICE SIZE/OFF NODE NAME
prometheu 13847 root 6u IPv6 63543 0t0 TCP *:8060 (LISTEN)
配置alertmanager
[root@node2 alertmanager-0.20.0.linux-amd64]# vim alertmanager.yml
重启alertmanager
[root@node2 alertmanager-0.20.0.linux-amd64]# ./alertmanager –config.file=alertmanager.yml
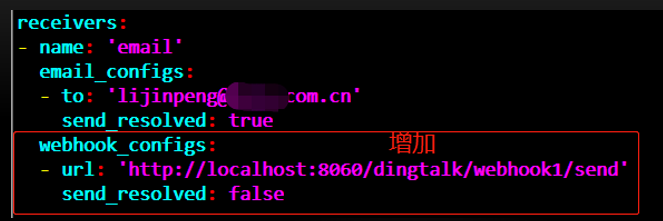
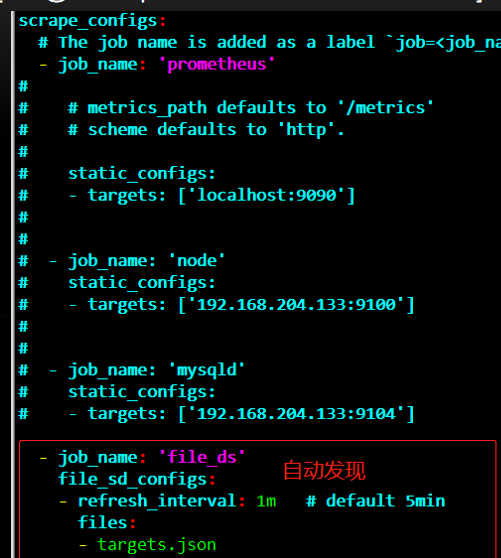
基于文件的自动发现
我们之前都是通过static_configs(静态)的方式,来让prometheus来pull(拉取)监控指标的。
如果我们再新增一个exporter监控程序,那么还得重启prometheus server。
那么现在我们需要一种不重启的,可以通过服务发现的方式,可以配置到file_sd
中。Prometheus server定时去扫这个文件,看看是否有新的exporter程序,就不需要进行重启server了。
编辑自动发现文件
[root@node2 prometheus-2.17.2.linux-amd64]# vim targets.json
[
{
"targets": ["192.168.204.133:9100"],
"labels": {
"job": "node",
"env": "prod"
}
}
]
配置自动发现
[root@node2 prometheus-2.17.2.linux-amd64]# vim prometheus.yml
重启server:
[root@node2 prometheus-2.17.2.linux-amd64]# ./prometheus –config.file=./prometheus.yml &
基于consul的自动发现
自动发现
static_configs: # 静态服务发现
file_sd_configs: # 文件服务发现
dns_sd_configs: # DNS 服务发现
kubernetes_sd_configs: # Kubernetes 服务发现
consul_sd_configs: # Consul 服务发现
Consul下载、安装、启动
Consul 是基于 GO 语言开发的开源工具,主要面向分布式,服务化的系统提供服务注册、服务发现和配置管理的功能。
Consul 提供服务注册/发现、健康检查、Key/Value存储、多数据中心和分布式一致性保证等功能。地址:https://www.consul.io/downloads.html
安装:[root@node2 soft]# mv consul /usr/local/bin/
启动:(单一节点)
[root@node2 soft]# consul agent -server -bind=0.0.0.0 -client=0.0.0.0 -bootstrap-expect=1 -data-dir=/u01/consul_data -node=node2 -ui
http注册
注册node_exporter:
[root@node2 ~]# curl -X PUT -d '{"id": "node","name": "node","address": "192.168.204.133","port": 9100,"tags": ["node"],"checks": [{"http": "http://192.168.204.133:9100/metrics", "interval": "5s"}]}' http://192.168.204.132:8500/v1/agent/service/register
注册mysqld_exporter:
[root@node2 ~]# curl -X PUT -d '{"id": ",mysqld","name": "mysqld","address": "192.168.204.133","port": 9104,"tags": ["mysqld"],"checks": [{"http": "http://192.168.204.133:9104/metrics", "interval": "5s"}]}' http://192.168.204.132:8500/v1/agent/service/register
Prometheus关联consul
[root@node2 prometheus-2.17.2.linux-amd64]# vim prometheus.yml
- job_name: 'consul' consul_sd_configs: - server: '192.168.204.132:8500' services: []重启prometheus server:
[root@node2 prometheus-2.17.2.linux-amd64]# ./prometheus –config.file=./prometheus.yml



