PS:以下内容,网友提供 欢迎投稿 cyylog@aliyun.com
性能优化
优化的目的
1. 提高资源的利用率
2. 找到性能瓶颈以及缓解这个瓶颈(CPU,内存,IO调度、网络、使用的应用程序)
3. 通过性能管理实现合理的资源分配,以及提升硬件的性价比
4. 通常做两种调优:
response time: 响应时间 Web服务器,用户感受度好
throughput: 吞吐量 文件服务器,拷贝的速度调优需要掌握的技能:
系统当前状况如何是不是有瓶颈的
1. 必须了解硬件和软件
2. 能够把所有的性能、指标量化,用数字说话
3. 设置一个正常期待值,比如将响应速度调到1.5秒
(企业版操作系统在出厂时已经调优,适用于普遍的应用,再根据个人的环境进行微调)
4. 建议有一定的开发能力
5. 想要更好的调优,需要更多的经验的积累,从而有一定洞察力,调节时所给参数才最恰当性能调优分层及效率问题:
- 业务级调优
例如:网站一定要使用Apache吗?
例如:将原有的调度器由LVS换成F5-BigIP? redware
例如:将原有的调度器由Nginx换成Haproxy?
例如:能不能购买CDN? 内容发布网络
例如:通否增加服务器数量?
例如:将原有的Memcache换成Redis?
例如:将原有的MySQL Proxy换成MyCat?
- 应用级调优
NFS,Samba,Apache、Nginx、php-fpm、MySQL、Oracle、KVM、LVS、PHP本身调优
对于日志的处理rsyslog:可以调整记录的日志等级或延后日志写,从而避免大量的I/O操作
禁用一些不必要的服务如蓝牙、smart card,makewhatis, updatadb
从运维人员角度来说无非就是参数的修改和配置
- kernel级调优
操作系统系统层面,即kernel调优具有普遍性:I/O CPU Network Memory,通常在系统初始完成
vm.dirty_expire_centisecs = 2
net.ipv4.tcp_tw_recycle = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_synack_retries = 5
考虑的是怎么让应用程序在我们系统上运行的更合理规范,或者说在硬件不变动的情况下,对系统优化提高性能和效率 优化效果
1.当前配置是否适合当前的运行环境和用户需求(如果是memcache 那我们考虑更多的可能是内存的消耗是不是更大些,如果是apache的话我们考虑的话可能就是cpu的消耗,所以所有的优化手段都要根据具体的环境,如果是编译需要的内存和cpu)
2.硬件的提升效果会更好,自上往下,效果越来越不明显优化
==调整系统kernel/应用的性能参数
==合理资源分配PAM,Cgroup(Docker)
==架构优化,Nginx负载集群、MySQL读写分离/Galera Cluster
# man proc /drop_cache
Kernel级别的优化:查看内核文档
# yum -y install kernel-doc
# ls /usr/share/doc/kernel-doc-3.10.0/Documentation/sysctl/
00-INDEX abi.txt fs.txt kernel.txt net.txt README sunrpc.txt vm.txt
# grep "_reuse" -R /usr/share/doc/kernel-doc-3.10.0/Documentation/
/usr/share/doc/kernel-doc-3.10.0/Documentation/networking/ipvs-sysctl.txt:conn_reuse_mode - INTEGER
/usr/share/doc/kernel-doc-3.10.0/Documentation/networking/ip-sysctl.txt:tcp_tw_reuse - BOOLEAN
# # grep "drop_caches" -R /usr/share/doc/kernel-doc-3.10.0/Documentation/
/usr/share/doc/kernel-doc-3.10.0/Documentation/sysctl/vm.txt:drop_caches获取硬件信息
硬件方面,主要要调优的对象
CPU
Memory
Storage
Networking
基本知识
基本知识: 所有存储类的设备
离CPU越近会越快,离CPU越远将越慢
离CPU越近存储的容量越小,离CPU越远存储的容量越大
离CPU最近的是寄存器,寄存器的时钟周期和CPU是一样的
离CPU稍远的存储:
L1,在CPU中,静态内存,工艺复杂
L2,使用的是动态高速内存
L3
L4
Memory
Storage TB, PB
# lscpu
L1d cache 一级数据缓存
L1i cache 一级指令缓存
L2 二级缓存(L2是否共享?)
Thread(s) per core: 线程数为1,不支持超线程
Core(s) per socket: CPU核数
Socket(s): 1 几路
NUMA node(s): 1 不支持NUMA
# x86info -c 查看CPU型号
# getconf -a 显示所有系统配值变量值
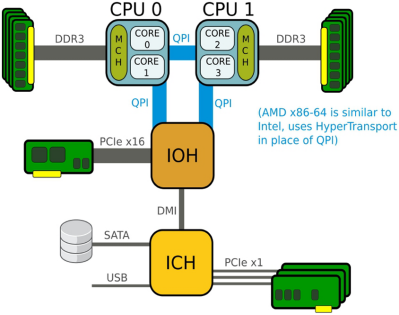
根据CPU访问内存的方法:
a. UMA:一致性内存访问,传统架构
MCH: 内存控制芯片,即北桥
ICH: I/O控制芯片,即南桥,连接外设,硬盘,USB,慢速PCI总线设备
b. NUMA:非一致性内存访问(内存分为多片,而不是UMA时的一片内存)
IOH: I/O HUB,也可以叫北桥
NUMA 架构显著的特色是:内存划分成片,CPU访问本区的内存的时候,速度非常快
Memory的相关指标
# cat /proc/meminfo
# free
# top
# vmstat
Memory size:
内存效率重要指标:
a. bandwidth: 带宽,使用的是DDR几代;例如PC2100,指2100M/s的吞吐量,即带宽
b. latency: 延迟,纳秒级ns
c. ECC内存 存储的相关指标
主要的调优对像,对内存而言,特别慢
拿16G的内存存数据!
拿16G的硬盘存数据!
当前两种磁盘类型:
机械磁盘: 盘片
电子SSD: 固态磁盘
机械磁盘:
昂贵的寻道时间 Expensive seek time
主轴转速: 7200RPM 10000RPM(10k) 15000RPM(15k)
缺点:容易坏
优点:存储量非常高,价格低
Burst speed: 突发速率,最快读写速率,指的是顺序读写 Sequential access
average speed: 平均读写速率,生产中不能保证是顺序读写 Random access
调优: 进行大量的优化合并
SSD:
Electronic disk: 电子磁盘,没有机械部件
No start-up time,读和写延迟非常低
安静,发热量小,不怕震动,而且很轻,用电少
价格高:在同等容量下比较
寿命相对短
连接的方式:
内部存储: IDE(PATA),SATA,SAS,FC
外部存储: SCSI线连接, SAS线连接,SATA线连接,Fibre Channel, ISCSI,网络带宽,延迟,多路径都会影响到外部存储的速度
4k/sector support: 4k对齐,效率更高(默认扇区大小512B)
外圈快,内圈慢:
磁盘转一圈,外圈读的扇区数多,所以数据写读时外圈快,内圈慢
RHEL安装时,默认将/, /boot分区扔到了最快圈,交换区自动选择内圈(它认为swap不需要经常访问)
Networking Profile
带宽
延迟
尽量把不同的网络隔离开,让其处于不同的广播域,划分VLAN
使用bonding或Team技术实现多网卡绑定,从而实现HA或LB(提高带宽)
高端网卡支持虚拟化SR-IOV
高端网卡有自己的处理芯片,网络上的数据到达时,不需要中断CPU
其它获得硬件性能指标工具
dmidecode 直接查BIOS信息
dmidecode -t 0 type 0主要是硬件信息
powertop 查看最耗电进程
lspci
lsusb
ethtool
=================================================================================
//检测是否有该设备
[root@install ~]# lspci |grep -i eth
03:00.0 Ethernet controller: Broadcom Corporation NetXtreme II BCM5708 Gigabit Ethernet (rev 12)
05:00.0 Ethernet controller: Broadcom Corporation NetXtreme II BCM5708 Gigabit Ethernet (rev 12)
[root@install ~]# lspci |grep -i fib
12:02.0 Fibre Channel: Emulex Corporation Thor LightPulse Fibre Channel Host Adapter (rev 01)
12:02.1 Fibre Channel: Emulex Corporation Thor LightPulse Fibre Channel Host Adapter (rev 01)
# ethtool eth0
Settings for eth0:
Supported ports: [ TP MII ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Half 1000baseT/Full
Supported pause frame use: No
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Half 1000baseT/Full
Advertised pause frame use: Symmetric Receive-only
Advertised auto-negotiation: Yes
Link partner advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Half 1000baseT/Full
Link partner advertised pause frame use: Symmetric
Link partner advertised auto-negotiation: Yes
Speed: 1000Mb/s
Duplex: Full
Port: MII
PHYAD: 0
Transceiver: internal
Auto-negotiation: on
Supports Wake-on: pumbg
Wake-on: g
Current message level: 0x00000033 (51)
drv probe ifdown ifup
Link detected: yes
# ethtool -i eth0
driver: r8169
version: 2.3LK-NAPI
firmware-version: rtl8168e-3_0.0.4 03/27/12
bus-info: 0000:04:00.0
supports-statistics: yes
supports-test: no
supports-eeprom-access: no
supports-register-dump: yes
supports-priv-flags: no
# mii-tool eth0
eth0: negotiated 100baseTx-FD flow-control, link ok
//是否加载相应的驱动
[root@install ~]# dmesg |grep -i fib
Emulex LightPulse Fibre Channel SCSI driver 8.3.39
scsi3 : Emulex LP1050 PCI-X Fibre Channel Adapter on PCI bus 12 device 10 irq 19
scsi4 : Emulex LP1050 PCI-X Fibre Channel Adapter on PCI bus 12 device 11 irq 18
查看FC HBA wwn号
[root@install ~]# cat /sys/class/fc_host/host3/port_name
0x10000000c9672e4a
[root@install ~]# cat /sys/class/fc_host/host4/port_name
0x10000000c9672e49
至强CPU
Intel E3,E5,E7代表了3个不同档次的至强CPU,至强“E系列”的这种命名方式有些类似桌面上的Core i3,i5,i7;比较通俗易懂的解释就是可以对应我们的豪华汽车生产商宝马3系,5系和7系。分别对应好,更好和最好。
其中:
至强E3处理器是第一款使用Haswell微架构的至强处理器芯片(目前,英特尔的多数芯片是以Ivy Bridge架构为基础),最多配置4个内核,最高支持32GB内存,耗电量只有13瓦,主要用于工作站和单路服务器;
至强E5处理器主要用于中档服务器,最高支持768GB内存,耗电量为60至130瓦,适用入门级双路服务器、高性能双路和四路服务器,也是目前使用最为广泛的主流处理器;
至强E7处理器是英特尔性能最高的服务器处理器,芯片包括30GB三级缓存,最高支持4TB内存,耗电量为130瓦。这种处理器可用于8路服务器。
至于具体应用可以根据处理器的型号来判定,以英特尔最新发布的E5-2600 V2为例,这里的“2”,也就是连字符后的第一个数字,它代表处理器最多支持的并行路数,有1、2、4、8四种规格,分别代表了单路、双路、四路和八路。我们现在举例的这款E5-2600 至强CPU,连字符后的第一个数字是"2",就表示这款CPU为双路,只能用于对应的双路芯片组的主板。
紧接着,我们来看连字符后的第二个数字,它代表处理器封装接口形式,一共有2,4,6,8四种规格,分别是2对应Socket H2(LGA 1155)、4对应Socket B2(LGA 1356)、6对应Socket R(LGA 2011)、8对应Socket LS(LGA 1567)。我们举例的这款E5-2600,连字符后的第二个数字是"6",对应Socket R(LGA 2011)
然后,连字符后第三和第四位代表编号序列,一般是数字越大产品性能越高,价格也更贵。
最后,看连字符后第四位数字后面的代表什么。紧跟第四位数字后的"L"代表是低功耗版,留空的话就代表是标准版。
连字符后面最后的数字代表修订版本,比如v2、v3、v4等等,这次新发布的E5-2600 V2就是第二次升级版。
注:
LGA 1155:表示不同的封装技术CPU
cpu的相关指标
# cat /proc/cpuinfo
物理的(多少路),核心的,超线程
多路服务器:
双路四核,是指服务器/工作站有两个CPU,每个CPU都是四核处理器。
多路服务器/工作站的关键部件是多路主板,可安装多个处理器,双路主板举一示例如图:
一个CPU,配一套内存,双路就是双CPU加双套内存
CPU调度
cpu调度:
3个进程
a b c 都是R cpu处理谁? 这样就要依靠调度程序?
a----b-----c 批处理操作系统
同样3个进程
a b c 每个运行1秒 好像是cpu独占 分时操作系统
哪种系统操作完消耗的时间少?批处理操作系统
OS从cpu的调度来分:
分时
分时操作系统以"分时"原则,为每个用户服务.将CPU的时间划分成若干个片段,称为时间片。操作系统把每个时间片分,轮流地切换给各终端用户的程序使用。由于时间间隔很短,每个用户的感觉就像他独占计算机一样。分时操作系统的特点是可有效增加资源的使用率。例如UNIX系统就采用剥夺式动态优先的CPU调度,有力地支持分时操作。
批处理
批处理(batch processing )就是将作业按照它们的性质分组(或分批),然后再成组(或成批)地提交给计算机系统,由计算机自动完成后再输出结果,从而减少作业建立和结束过程中的时间浪费。
如:打印机就是采用这种操作系统
实时
实时操作系统(RealTimeOperatingSystem,RTOS)是指使计算机能及时响应外部事件的请求在规定的严格时间内完成对该事件的处理,并控制所有实时设备和实时任务协调一致地工作的操作系统。实时操作系统要追求的目标是:对外部请求在严格时间范围内做出反应,有高可靠性和完整性。其主要特点是资源的分配和调度首先要考虑实时性然后才是效率。此外,实时操作系统应有较强的容错能力。
区别:
批处理系统(batch processing system)中,一个作业可以长时间地占用cpu。而分时系统中,一个作业只能在一个时间片(Time Slice,一般取100ms)的时间内使用cpu。
批处理系统的目的:提高系统吞吐量和资源的利用率。
分时系统的目的: 对用户的请求及时响应,并在可能条件下尽量提高系统资源的利用率。
进程与调度:
进程:
程序是一个文件,而process是一个执行中的程序实例。
linux系统中创建新进程使用fork()系统调用。
利用分时技术,在linux操作系统上同时可以运行多个进程,当进程的时间片用完时,kernel就利用调度程序切换到另一个进程去运行。
内核中的调度程序:
用于选择系统中下一个要运行的进程。你可以将调度程序看做在所有处于运行状态的进程之间分配CPU运行时间的管理代码。为了让进程有效的使用系统资源,又能让进程有较快的响应时间,就需要对进程的切换调度采用一定的调度策略。时钟频率
CPU timer 固定频率给CPU发中断,CPU可停下来通过调度器处理下一个任务
#grep HZ /boot/config-x.x.x
#grep HZ /boot/config-2.6.32-358.el6.x86_64
CONFIG_NO_HZ=y
# CONFIG_HZ_100 is not set
# CONFIG_HZ_250 is not set
# CONFIG_HZ_300 is not set
CONFIG_HZ_1000=y ---------------------------1秒1000次
CONFIG_HZ=1000
CONFIG_MACHZ_WDT=m
所有的linux操作系统都是基于中断驱动的:
当我们在键盘上按下一个按键时,键盘就会对CPU说,一个键已经被按下。在这种情况下,键盘的IRQ线路中的电压就会发生一次变化,而这种电压的变化就是来自设备的请求,就相当于说这个设备有一个请求需要处理。
[root@mail ~]#watch -n 1 cat /proc/interrupts //包含有关于哪些中断正在使用和每个处理器各被中断了多少次的信息。
CPU0
0: 174 IO-APIC-edge timer
1: 70 IO-APIC-edge i8042
3: 1 IO-APIC-edge
4: 1 IO-APIC-edge
7: 0 IO-APIC-edge parport0
8: 0 IO-APIC-edge rtc0
9: 0 IO-APIC-fasteoi acpi
12: 1397 IO-APIC-edge i8042
14: 0 IO-APIC-edge ata_piix
15: 4180 IO-APIC-edge ata_piix
16: 945 IO-APIC-fasteoi Ensoniq AudioPCI
17: 778014 IO-APIC-fasteoi ehci_hcd:usb1, ioc0
18: 0 IO-APIC-fasteoi uhci_hcd:usb2
19: 487 IO-APIC-fasteoi eth0
第一列表示IRQ号,IRQ号决定了需要被CPU处理的优先级。IRQ号越小意味着优先级越高。
第二、三、四列表示相应的CPU核心被中断的次数。IO-APIC-edge表示终端接口,timer表示中断名称(为系统时钟)。174表示CPU0被中断了174次。i8042表示控制键盘和鼠标的键盘控制器。对于像rtc(real time clock)这样的中断,CPU是不会被中断的。因为RTC存在于电子设备中,是用于追踪时间的。NMI和LOC是系统所使用的驱动,用户无法访问和配置。
例如,如果CPU同时接收了来自键盘和系统时钟的中断,那么CPU首先会服务于系统时钟,因为他的IRQ号是 0 。
IRQ0 :系统时钟(不能改变)
IRQ1 :键盘控制器(不能改变)
IRQ3 :串口2的串口控制器(如有串口4,则其也使用这个中断)
IRQ4 :串口1的串口控制器(如有串口3,则其也使用这个中断)
IRQ5 :并口2和3 或 声卡
IRQ6 :软盘控制器
IRQ7 : 并口1。它被用于打印机或若是没有打印机,可以用于任何的并口。
调整:每接收到一个时钟中断就要处理另一个任务.调度器----根据调度算法
频率高 响应速度高 吞吐量低
频率低 响应速度底 吞吐量高
桌面推荐高频率,服务器推荐低频率
对于应用程序的运行,最好的办法是纵向升级(提升CPU频率)而不是横向升级(增加CPU数量)。这取决于你的应用程序是否能使用到多个处理器。例如一个单线程应用程序的升级方式最好是更换成更快的CPU而不是增加为多个CPUPS命令
ps命令:
ps -o user,pid,%cpu -p 3288
ps -eo user,pid,%cpu --sort %cpu //升序 -%cpu 降序
top命令
#top -d 1
top - 10:18:15 up 1:45, 4 users, load average: 2.44, 2.42, 1.82
Tasks: 225 total, 3 running, 222 sleeping, 0 stopped, 0 zombie
Cpu(s): 79.2%us, 17.6%sy, 0.0%ni, 0.3%id, 0.0%wa, 0.0%hi, 2.8%si, 0.0%st
Mem: 4019424k total, 2419520k used, 1599904k free, 248248k buffers
Swap: 8191992k total, 0k used, 8191992k free, 525780k cached
----------------------------------------------------------
快捷键:
P 按cpu排序
M 按内存排序
f 添加删除字段,带*的是默认显示 大写的是当前显示 小写的是现在没有显示的 可以关掉指定的列,开启需要的列,按对应的字母就可以
1 可以展开cpu,也就是如果有多个cpu可以这样查看 ,没有展开之前是平均值
top后按1,然后按W,会将此次的显示配置保存到 ~/.toprc 文件中,下次再top的时候就会直接显示多CPU使用率。
可以在脚本中直接使用top的Batch模式
#top -bn1一台服务器是否稳定
up后面的时间可以作为判断标准之一
load average: 1 5 15
1分钟,5分钟,15分钟之前到现在的cpu平均负载(等待cpu处理的进程队列平均长度)
负载:
正在运行的进程
进入到IO等待位置的进程
我是cpu 你们是程序 没人跟我说话 我现在是没有负载的
有一个人问问题 我有负载吗?
没有
如果再有一个人问问题,如果之前同学的问题处理完了或者他俩的问题很简单,我一次就解决完了,这时候是没有负载的
如果第一个问的问题很困难,我一时解决不完,这时候再有人问问题的时候我就产生负载了
1分钟之内举例:
0 10 20 30 40 50 60 CPU
A 只用了10秒,这时候cpu的负载是1/6
B 用了20秒, 这时候负载是1/2
C 用30秒, 这时候负载是1
最好的单核CPU负载是1
加上cpu核数,最好的负载是跟核数相等,
核数的2倍以内没什么大问题,2倍以上说明负载过高
8核
负载 25 15 3 ,这样的负载是没什么问题的
但是一定要判断到25那个地方发生了什么事情,能不能把那个峰值化解掉,不然如果峰值越来越高,那么服务器可能承受不住
比如邮件服务器的收发高峰和邮件备份产生的负载高峰,我们可以把他们两个操作分开成两个小高峰,这样最好
-----------------------------------------------------------
running
两个含义
1.正在运行
2.可运行的 //也就是此程序必须在调用cpu之前要准备好运行
sleeping 可以叫睡眠,等待或者阻塞
stoped表示挂起(暂停)
------------------------------------------------------------
%us 用户态程序占用cpu百分比
%sy 内核态程序占用cpu百分比
%ni 调整过nice值的程序占用cpu百分比
%id cpu空闲百分比
%wa io等待消耗cpu的百分比(cpu空转)
%hi 硬件中断占用cpu的百分比
%si 软中断
%st cpu被偷走的百分比
……………………………………………………
内核态和用户态
当一个任务(进程)执行系统调用而陷入内核代码中执行时,我们就称进程处于内核运行态(或简称为内核态)。此时处理器处于特权级最高的(0级)内核代码中执行。当进程处于内核态时,执行的内核代码会使用当前进程的内核栈。每个进程都有自己的内核栈。当进程在执行用户自己的代码时,则称其处于用户运行态(用户态)。即此时处理器在特权级最低的(3级)用户代码中运行。当正在执行用户程序而突然被中断程序中断时,此时用户程序也可以象征性地称为处于进程的内核态。因为中断处理程序将使用当前进程的内核栈。这与处于内核态的进程的状态有些类似。
例:
#cat /etc/passwd
在用户级别执行cat //这些开销就是用户的开销
要用cat查看文件,必须得去硬盘上找文件,那么需要有硬盘驱动,这样就会需要内核,所以就会用到系统调用,因为有了系统调用才能跟内核对话 //这些开销就是内核态的开销
在内存里就会有一个cat命令的进程 把cat命令所需要的Lib库准备好
常用的系统调用
open()
read()
write()
close()
us > sy
用户的开销一般大于系统开销
us一般不会超过%70,如果大于%70,那看看是不是运行的程序是否过多或者一个类似死循环的程序
sy一般不会超过%30,如果大于%30,那看看是不是运行了大量的内核态程序,比如iptables和lvs都是内核态程序
……………………………………………………
ni nice值的调整可能两种情况:系统自动去调整或者人工调整 那么这里的百分比是指人工调整
id 空闲太高不好,浪费资源,那么在20-30之间最好
如果%idle 的值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量
如果%idle 的值持续低于1,则系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU 。
wa
a在运行过程当中要产生10G数据,现在先产生了2G,cpu说你先停,你先把这2G写到硬盘上,但是现在硬盘慢,cpu要等,所以他可以去找b去运行,现在b程序发生了和a一样的情况,也在往硬盘写数据,那么cpu现在干什么?在等,这时候的等待状态我们称他为空转状态,所以通过这个数值可以判断硬盘慢不慢
如果%iowait 的值过高,表示硬盘存在I/O瓶颈
hi
中断:对cpu当前操作的一个打断
硬中断,也就是硬件产生的中断(比如键盘,鼠标,网卡)在实际工作当作,网卡产生的中断最多,
si 软件中断,比如说计划任务
硬中断优先级比软中断优先级高
st 这个数值是针对虚拟机的 他的值我们看不到
vm1 vm2 //虚拟机
vcpu vcpu //虚拟cpu
cpu //真实cpu
假如现在vm1正在使用vcpu,那么他实际上用的是cpu,那么这时候如果vm2要使用cpu的话,不能用,因为现在cpu正被vm1偷走了
-------------------------------------------------------------
buffers cached
cached这个是属于mem那一行的,说是这里放不下了所以才放到了下面
两者都是RAM中的数据。简单来说,buffer是即将要被写入磁盘的,cache是被从磁盘中读出来的。
buffer是由各种进程分配的,被用在如输入队列等方面,索引缓存,存inode信息。一个简单的例子如某个进程要求有多个字段读入,在所有字段被读入完整之前,进程把先前读入的字段放在buffer中保存。
cache经常被用在磁盘的I/O请求上,存block信息,如果有多个进程都要访问某个文件,于是该文件便被做成cache以方便下次被访问,这样可提高系统性能。
手动释放buffers和cached:
#echo 3 > /proc/sys/vm/drop_caches
=======================
优先级
作用:
1、优先级高会被优先调度。
2、时间片会不同。
范围:
早先优先级范围 nice范围
0 -20
20 0
39 19
0~39 -20~19
现在:
0-139 linux优先级的整个范围,其中0号为优先级最高,139为最低
0-99 RT实时进程(静态)优先级范围 , 0号保留,设置时使用1-99
100-139 非实时进程(动态)的优先级别范围 (由nice值映射过来)
分类:
动态优先级和静态优先级
top里面显示的PR是动态优先级,数值越小有限级越高
SYSV又加了60个优先级 ,那60个优先级就是静态优先级
现在Linux在之前40个优先级的基础上加了100个静态优先级,RT
实时优先级肯定大于非实时优先级
实际优先级范围是99优先级最大,0最小,在往后,从RT的角度来看全是0,但是实际是0-39
0--------------------99 100-----------139 整个优先级范围
-99---FIFO RR---------0--------------0 从RT的角度看后面优先级都是0
0--------------39 后面部分实际优先级
查看实时进程优先级:
# chrt -p 5752 //pid为5752的进程在top内显示PR为20,但是在从RT的角度来看是0
pid 5752's current scheduling policy: SCHED_OTHER
pid 5752's current scheduling priority: 0
优先级一样的时候先执行谁?
早期:单cpu,单用户,单任务
在运行一个应用程序的时候,使用内存,会有空闲内存,cpu空闲,硬盘空闲
但是当时的硬件配置相当低(比如4k的内存),而且执行很快(汇编写的程序),所以也不会出现资源浪费,那么现在随着硬件的性能提高就会出现资源浪费现象
现在:多cpu,多用户,多任务
假如有一个应用程序占用CPU时间太长,那么后面的程序会无法执行
所以内核会对同优先级的程序进程判断是cpu消耗型还是IO消耗型,IO消耗型的程序并不是不使用cpu,只是用的时间很短,所以我们让他们两个都可以运行,但是在io消耗型程序使用cpu的时候临时给他调整一下优先级
内核可以让cpu消耗型在+5范围内优先级进程偏移,io消耗型在-5范围内优先级进程偏移,所以这里的优先级是动态优先级,
程序分为几种:1.cpu消耗型(计算) 2.IO消耗型(通常如果不是恶意程序,基本上就是IO消耗型,比如QQ,只有在收发信息的一瞬间才会消耗cpu。听歌消耗的是硬盘和声卡也是IO消耗型)
cpu消耗型的 pri值为80~85 85标准cpu消耗型,如:死循环
io消耗型的 pri值为75~80 75标准io消耗型,往往是和用户交互的程序,如:bash,vi,下载 本身占CPU并不多,但I/0消耗多
调整优先级:
可以通过renice命令调整nice值,pri值调整不了,系统自已评估.
我们设置优先级别,设置的是nice 值,实际系统看的是pri值。用户调整nice值,系统会干预pri值
系统要考虑在两种进程的nice值一样的情况下,i/o消耗型的进程应该优先级别更高一些(也就是pri值更小)
ps -l
pri ni
77 0 ps
75 0 bash
bash 典型的I/0消耗型,pri值大概为75
pri是系统以nice值为基数的调整
pri 浮动范围 85 <---- 80 -----> 75
CPU I/O
进程队列中如果有实时进程除非它释放资源,才执行非实时进程.当然实时进程也有优先级别高的,先执行完高优先级的才执行一下个进程.调度策略
查看所有调度策略:
#chrt -m
SCHED_OTHER min/max priority : 0/0
SCHED_FIFO min/max priority : 1/99
SCHED_RR min/max priority : 1/99
SCHED_BATCH min/max priority : 0/0
SCHED_IDLE min/max priority : 0/0
1/99是实时进程使用的调度策略
0/0非实时进程使用的调度策略
FIFO 先进先出,谁先来,处理谁
RR 分时算法,程序被分配时间片,每个程序使用一会儿
OTHER 跟RR一样论询,如果没有特殊情况跟RR一样
BATCH 批处理,来5个人处理一次
IDLE
FIFO 和 RR 属于实时进程(也叫静态优先级进程)的调度策略。优先级高于非实时进程(动态优先级进程) BATCH和OTHER ,如果一个实时进程准备运行,调度器总是试图先调度实时进程。
BATCH是2.6内核新加入的策略,这种类型额进程一般都是后台处理进程,总是倾向于跑完自己的时间片,没有交互性,对于这样的调度策略,调度器一般给的优先级比较低。如果有一个程序设置成BATCH,cpu会尽量给这个程序使用,但是一旦有OTHER,那么先给OTHER策略的程序 ,也就是OTHER优先级高
IDLE是只要有其他程序运行,我就不运行,也就是只有在cpu空闲的时候就把这个程序设置成IDLE
OTHER>BATCH>IDLE
IDLE的nice值比19还要低,rhel6新出的,rhel5没有
修改调度策略:
#chrt 调度中实时进程的优先级可以让一个非实时进程以实时进程的方式运行,也相当与提高了这个进程的优先级
#cat 执行一个cat命令
#ps -e | grep cat 查看PID
6183
#chrt -p 6183 查看默认策略
#chrt -p 10 6183 优先级改成10,默认策略变成RR
#chrt -f 20 cat 在开始运行cat命令的时候制定优先级,策略为FIFO
top 中有RT字样的是实时进程:
例如:
2 root RT -5 0 0 0 S 0.0 0.0 0:00.00 migration/0
# ps -el //结果中NI值为-的是实时进程
只要实时进程处于r状态 那么非实时进程就没有时间片了
pid 10以内的进程为内核进程 是内核的一部分cpu亲和力
cpu亲和力(也就是cpu绑定)
系统资源不够用,一台机子上跑了几个比较重要的服务,每天我们还要在上面进行个备份压缩等处理,网络长时间传输,这就很影响本就不够用的系统资源;
这个时候我们就可以把一些不太重要的比如copy/备份/同步等工作限定在一颗cpu上,或者是多核的cpu的一颗核心上进行处理,虽然这不一定是最有效的方法,但可以最大程度上利用了有效资源,降低那些不太重要的进程占用cpu资源;
cpu绑定:
把一个程序绑定到一个cpu上去执行
好处:
1.多核cpu使用的时候,内核会优先使用0,1号cpu,假如有4核,2,3号可能会利用率比较低,那么我们可以把不同的程序绑定到2,3号cpu上以提高cpu使用率
2.可以提高缓存命中率
安装软件:
util-linux-ng-2.17.2-12.9.el6.x86_64
查看cpu绑定:
# taskset -p 1
pid 1's current affinity mask: 3
affinity //cpu亲和力(也就是cpu绑定)
假如4核cpu:3 2 1 0 cpu编号从0开始
2^3+2^2+2^1+2^0=和 再把和换算成16进制就是mask后面的值,可以利用这个算式和值找到我们正在使用哪个cpu
绑定cpu:
#taskset -c 1,2 cat
把cat程序绑定到1号和2号cpu上执行
修改已经启动进程的cpu绑定:
# taskset -pc 0 11358
让进程11358运行在0号cpu上
=======================================
多并发:
多核情况下以线程方式运行效果更好一些,单核的话区别就不大了
进程和线程 有本质的区别
线程模式 创建和撤销开销小 资源竞争问题
进程模式 创建和撤销开销大 没有资源竞争问题
如apache 线程和进程模式 多核
每秒处理并发访问量 达到1000 ,这时线程表现较好
测试:
#ab -n 1000 -c 1000 http://localhost
当2000时 apache 挂了 ab命令最多支持2个万测试
测试nginx
单进程和多进程
加大页面内容
cps 每秒的并发连接数(TCP)
qps 每秒的并发请求数 GET/HEAD/DELETE/PUT
--------------------------------------
平衡cpu中断:
上下文切换:
cpu读取数据的时候会从L1,L2,L3等一级二级三级缓存里面读,先去L1找,L1没有,去L2里找,L2没有,去L3找,L3没有找内存,内存没有找硬盘。
如果A被处理要把A放到L1里面,那么现在B需要处理,所以需要把B放到L1里,那么原来L1里的A清除掉,这就是上下文切换
当产生中断的时候就会产生一次上下文切换
a还没有运行完的时候,出现一个中断信号,cpu会处理这个中断,处理完成再回来处理a
那么打断多了好还是少了好?不一定,多有多的好处,少有少的好处
打断少了会增加吞吐量,但是响应就会变慢
所以在中断的时候要考虑是要吞吐量还是要响应能力
假如我是4核cpu:
我们发现大部分中断都集中在一个cpu上,所以我们可以平衡中断,把中断平分到其他cpu上去
#cat /proc/interrupts 显示系统内已经注册的中断
第1列注册了的中断编号 第2,3,4,5列 每个cpu处理了多少次中断
自动平衡,rhel6直接启动这个命令就可以
#/etc/init.d/irqbalance start
rhel5里面没有自动平衡,只能手工平衡
rhel6如果想手工平衡的话,需要关闭上面的irqbalance服务
手工平衡实验:
确定想调整谁,就记住他的中断编号,然后去/proc/irq/里面找到相应的编号,比如23 /proc/irq/23
#cat /proc/irq/23/smp_affinity 这个文件里的值就是亲和力,算法一样跟之前一样
实验:
#watch -n 1 cat /proc/interrupts 1秒钟监控一次后面的程序
然后拿另一台机器一直ping这台监控机器,我们发现网卡中断在cpu0上,那么现在要求把网卡中断交给cpu1处理
28: 25202611 1428501 PCI-MSI-edge eth0
#echo 2 > /proc/irq/28/smp_affinity
发现中断会跑到第2块儿cpu上
cpu监控
相关监测命令
系统负载 uptime
举例:
处理器 1
1分钟的负载值 <=3
CPU使用率
TOP工具: 第三排信息值
Cpu(s): 消耗CPU处理时间的百分比 (iostat 看更全的单词)
95.8%us, 用户态
1.1%sy, 内核态
2.6%ni, 优先级切换
0.0%id, CPU空闲 ***
0.0%wa, 等待,IO输入输出等待
0.0%hi, 硬中断 什么叫中断呢? 每个硬件都有会中断地址/proc/interrupts
0.5%si, 软中断
0.0%st CPU偷窃时间 ,与xen虚拟化有关系
[root@xen ~]# iostat
Linux 2.6.18-194.el5xen (xen.pg.com) 2011年01月18日
avg-cpu: %user %nice %system %iowait %steal %idle
2.75 0.75 1.31 1.89 0.01 93.29
Device: tps Blk_read/s Blk_wrtn/s Blk_read Blk_wrtn
sda 7.46 152.21 82.99 1240948 676550
sda1 1.05 11.99 0.03 97781 256
sda2 0.00 0.00 0.00 6 0
sda5 0.12 5.22 0.00 42549 0
sda6 0.05 1.30 0.00 10621 16
sda7 0.01 0.22 0.00 1818 38
sda8 0.01 0.16 0.00 1315 0
sda9 6.22 133.26 82.95 1086402 676240
观测占用CPU时间
top (这个命令本身就挺消耗CPU时间的)
找出 R 状态的进程。
临时: 使用renice 调整进程的优先级。
治本: 要明确这个进程的功能了。
如果有问题的,结束,修改程序。
如果没有问题,是正常的进程。花钱买CPU。
举例:
WEB服务器(PHP)
CPU负载跟CPU使用率都很高,而且CPU不能扩充。
怎么办?
“集群“
进程列表:
ps 只对具体进程进行观测
#ps -eo "pid,comm,rss,pcpu" --sort pcpu 升序
#ps -eo "pid,comm,rss,pcpu" --sort -pcpu 降序
#ps -eo "pid,comm,rss,pcpu,rtprio,ni,pri,stat" --sort -pcpu 实时进程优先级 如果显示为空,说明不是实时进程
man ps
AIX FORMAT DESCRIPTORS
This ps supports AIX format descriptors, which work somewhat like the formatting codes of
printf(1) and printf(3). For example, the normal default output can be produced with this:
ps -eo "%p %y %x %c". The NORMAL codes are described in the next section.
CODE NORMAL HEADER
%C pcpu %CPU
%G group GROUP
%P ppid PPID
%U user USER
%a args COMMAND
%c comm COMMAND
%g rgroup RGROUP
%n nice NI
%p pid PID
%r pgid PGID
%t etime ELAPSED
%u ruser RUSER
%x time TIME
%y tty TTY
%z vsz VSZ
多核心监测
mpstat工具:
mpstat是Multiprocessor Statistics的缩写,是实时系统监控工具。其报告与CPU的一些统计信息,这些信息存放在/proc/stat文件中。在多CPUs系统里,其不 但能查看所有CPU的平均状况信息,而且能够查看特定CPU的信息。mpstat最大的特点是:可以查看多核心cpu中每个计算核心的统计数据;而类似工 具vmstat只能查看系统整体cpu情况
#mpstat -P ALL 1 1000
#mpstat [-P {|ALL}] [internal [count]]
参数 解释
-P {|ALL} 表示监控哪个CPU, cpu在[0,cpu个数-1]中取值
internal 相邻的两次采样的间隔时间、
count 采样的次数,count只能和delay一起使用
当没有参数时,mpstat则显示系统启动以后所有信息的平均值。有interval时,第一行的信息自系统启动以来的平均信息。从第二行开始,输出为前一个interval时间段的平均信息。
[root@xen ~]# mpstat
Linux 2.6.18-194.el5xen (xen.pg.com) 2011年01月18日
12时16分20秒 CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
12时16分20秒 all 2.70 0.62 1.19 1.64 0.00 0.00 0.03 93.82 212.95
[root@xen ~]# mpstat -P ALL
Linux 2.6.18-194.el5xen (xen.pg.com) 2011年01月18日
12时16分29秒 CPU %user %nice %sys %iowait %irq %soft %steal %idle intr/s
12时16分29秒 all 2.70 0.62 1.19 1.64 0.00 0.00 0.03 93.82 213.14
12时16分29秒 0 3.10 0.63 1.39 2.71 0.00 0.00 0.04 92.14 121.29
12时16分29秒 1 2.31 0.61 0.98 0.58 0.00 0.00 0.02 95.50 91.85
[root@xen ~]# mpstat -P 0 1 10 每隔一秒取一次,取10次
高级系统检查
sar -u
使用率
sar -q
系统平均负载
立刻采集显示 <interval> <count>
sar -q 1 10
sar -u 1 10 即时性的报告
获取CPU各个核心信息
sar -u -P ALL 1
[root@xen sa]# sar -I ALL 1
获取每个进程CPU使用率,注意默认这个数据不记录在数据库。
sar -x ALL 1 3 *
指定文件读取
sar -u -f /var/log/sa/sa28
输出SAR格式数据
sar -u 1 10 -o /tmp/ooo
根据时间过滤数据
sar -u -s 13:00:00 -e 13:05:01
[root@xen sa]# sar -u -f /var/log/sa/sa18 -s 09:50:01 -e 12:40:01
Linux 2.6.18-194.el5xen (xen.pg.com) 2019年01月18日
09时50分01秒 CPU %user %nice %system %iowait %steal %idle
10时00分01秒 all 2.08 0.00 0.32 0.15 0.01 97.44
10时10分01秒 all 1.74 0.00 0.36 0.21 0.01 97.68
10时20分01秒 all 3.04 0.00 0.33 0.02 0.01 96.60
10时30分01秒 all 6.22 0.00 1.16 0.15 0.01 92.45
10时40分01秒 all 2.79 0.17 0.75 0.16 0.01 96.13
10时50分01秒 all 5.55 9.29 9.93 15.51 0.03 59.68
11时00分01秒 all 4.32 0.50 1.28 0.49 0.01 93.40
11时10分01秒 all 0.03 0.00 0.02 0.00 0.01 99.94
11时20分01秒 all 0.03 0.00 0.03 0.06 0.01 99.87
11时30分01秒 all 0.04 0.00 0.01 0.03 0.01 99.91
11时40分01秒 all 0.04 0.08 0.04 0.04 0.01 99.79
11时50分01秒 all 3.06 0.00 0.67 0.03 0.01 96.23
12时00分01秒 all 2.72 0.00 0.70 1.17 0.23 95.17
12时10分01秒 all 0.64 0.00 0.28 0.04 0.05 98.99
12时20分01秒 all 3.52 0.00 0.66 0.04 0.07 95.70
12时30分01秒 all 4.52 0.00 1.05 0.04 0.08 94.31
12时40分01秒 all 4.31 0.08 1.22 0.05 0.08 94.27
Average: all 2.63 0.60 1.11 1.07 0.04 94.56
===============================================
通过上面那些工具可以搜集一段时间的数据,通过数据可以分析系统状态
比如在公司写服务器运行报告的时候,怎么写,可以写这些工具搜集的信息
实际上搜集那些信息不用我们自己去做,如果安装了sysstat工具,那么就会有下面的计划任务
# ls /etc/cron.d/sysstat
/etc/cron.d/sysstat 这个计划任务会给我生成下面的记录文件,这些记录文件记录了cpu,mem和net,io等等所有的信息
# cd /var/log/sa/
sa01 sa07 这些文件后面的数字是日志,比如01就是1号
# sar -f sa01 查看那些记录文件
[root@xen sa]# sar -f /var/log/sa/sa18
Linux 2.6.18-194.el5xen (xen.pg.com) 2019年01月18日
09时50分01秒 CPU %user %nice %system %iowait %steal %idle
10时00分01秒 all 2.08 0.00 0.32 0.15 0.01 97.44
10时10分01秒 all 1.74 0.00 0.36 0.21 0.01 97.68
10时20分01秒 all 3.04 0.00 0.33 0.02 0.01 96.60
10时30分01秒 all 6.22 0.00 1.16 0.15 0.01 92.45
10时40分01秒 all 2.79 0.17 0.75 0.16 0.01 96.13
10时50分01秒 all 5.55 9.29 9.93 15.51 0.03 59.68
11时00分01秒 all 4.32 0.50 1.28 0.49 0.01 93.40
11时10分01秒 all 0.03 0.00 0.02 0.00 0.01 99.94
11时20分01秒 all 0.03 0.00 0.03 0.06 0.01 99.87
11时30分01秒 all 0.04 0.00 0.01 0.03 0.01 99.91
11时40分01秒 all 0.04 0.08 0.04 0.04 0.01 99.79
11时50分01秒 all 3.06 0.00 0.67 0.03 0.01 96.23
12时00分01秒 all 2.72 0.00 0.70 1.17 0.23 95.17
12时10分01秒 all 0.64 0.00 0.28 0.04 0.05 98.99
12时20分01秒 all 3.52 0.00 0.66 0.04 0.07 95.70
12时30分01秒 all 4.52 0.00 1.05 0.04 0.08 94.31
12时40分01秒 all 4.31 0.08 1.22 0.05 0.08 94.27
Average: all 2.63 0.60 1.11 1.07 0.04 94.56
[root@xen sa]# sar -u -f /var/log/sa/sa18
Linux 2.6.18-194.el5xen (xen.pg.com) 2019年01月18日
09时50分01秒 CPU %user %nice %system %iowait %steal %idle
10时00分01秒 all 2.08 0.00 0.32 0.15 0.01 97.44
10时10分01秒 all 1.74 0.00 0.36 0.21 0.01 97.68
10时20分01秒 all 3.04 0.00 0.33 0.02 0.01 96.60
10时30分01秒 all 6.22 0.00 1.16 0.15 0.01 92.45
10时40分01秒 all 2.79 0.17 0.75 0.16 0.01 96.13
10时50分01秒 all 5.55 9.29 9.93 15.51 0.03 59.68
11时00分01秒 all 4.32 0.50 1.28 0.49 0.01 93.40
11时10分01秒 all 0.03 0.00 0.02 0.00 0.01 99.94
11时20分01秒 all 0.03 0.00 0.03 0.06 0.01 99.87
11时30分01秒 all 0.04 0.00 0.01 0.03 0.01 99.91
11时40分01秒 all 0.04 0.08 0.04 0.04 0.01 99.79
11时50分01秒 all 3.06 0.00 0.67 0.03 0.01 96.23
12时00分01秒 all 2.72 0.00 0.70 1.17 0.23 95.17
12时10分01秒 all 0.64 0.00 0.28 0.04 0.05 98.99
12时20分01秒 all 3.52 0.00 0.66 0.04 0.07 95.70
12时30分01秒 all 4.52 0.00 1.05 0.04 0.08 94.31
12时40分01秒 all 4.31 0.08 1.22 0.05 0.08 94.27
Average: all 2.63 0.60 1.11 1.07 0.04 94.56
[root@xen sa]# sar -q -f /var/log/sa/sa18
Linux 2.6.18-194.el5xen (xen.pg.com) 2019年01月18日
09时50分01秒 runq-sz plist-sz ldavg-1 ldavg-5 ldavg-15
10时00分01秒 0 220 0.03 0.12 0.17
10时10分01秒 0 220 0.25 0.10 0.10
10时20分01秒 0 220 0.02 0.07 0.08
10时30分01秒 0 220 0.16 0.19 0.12
10时40分01秒 0 225 0.32 0.22 0.13
10时50分01秒 4 227 1.65 1.28 0.69
11时00分01秒 0 220 0.00 0.24 0.40
11时10分01秒 0 220 0.00 0.02 0.19
11时20分01秒 0 221 0.00 0.00 0.08
11时30分01秒 0 221 0.00 0.00 0.02
11时40分01秒 0 221 0.08 0.02 0.01
11时50分01秒 2 221 0.42 0.22 0.08
12时00分01秒 0 229 0.17 0.13 0.08
12时10分01秒 0 232 0.00 0.01 0.03
12时20分01秒 2 228 0.30 0.16 0.09
12时30分01秒 1 228 0.33 0.18 0.11
12时40分01秒 1 228 0.31 0.20 0.11
Average: 1 224 0.24 0.19 0.15
===============================================
mem
内存的特点:
速度快,所存数据不会保存,内存的最大消耗来源于进程
测试内存速度:
安装软件:memtest86+-4.10-2.el6.x86_64.rpm
执行 memtest-setup命令 多出一个操作系统
内存存储的数据有那些?
程序代码,程序定义的变量(初始化和未初始化),继承父进程的环境变量,进程读取的文件,程序需要的库文件.还有程序本身动态申请的内存存放自己的数据
除了进程以外还有内核也要占用,还有buffer和cache,还有共享内存(如共享库)
我们使用管道符| 进程之间通讯也要使用到内存,socket文件
那我们可以优化哪部分程序?
内核内存不能省
buffer/cache不能省
进程通讯不省
系统支持的内存大小:
2的32次方 32位系统支持的内存 windows受到约束 linux只要换个pae(物理地址扩展)内核 可以支持2的36次方
2的64次方
查看系统内存信息
[root@localhost ~]# free -m
total used free shared buffers cached
Mem: 1010 981 29 0 145 649
-/+ buffers/cache: 186 824
Swap: 2047 0 2047
share 在6之前包括6,这个地方永远都是0,已经被废弃了,rhel7里面已经可以正常显示
# cat /proc/meminfo | grep -i shm share就是这个值,free和vmstat都是从/proc/meminfo文件里面搜集的信息
Shmem: 26620 kB
used包括buffers和cached,是已使用的内存+buffers+cached ,剩下的是free
-/+ buffers/cache: 186 824
186是减去buffers和cached之后的物理内存,824是总内存减去186之后的值
buffers 索引缓存 存inode信息
cached 页缓存 存block信息
catched实验:
# watch -n 0.5 free -m 监控内存信息
在另外一个窗口dd一个1G的文件,观察buffer和cache
# dd if=/dev/zero of=abc bs=1000M count=1
从/dev/zero里面读了1G数据到cache里面
dd之前:
total used free shared buffers cached
Mem: 3724 619 3105 0 59 242
dd之后:
total used free shared buffers cached
Mem: 3724 1652 2071 0 59 1246
buffers实验:
#find / 把/下所有文件都列出来 会读到directory block,通过inode找到文件名,有多少个文件就会读多少次目录块,所以我们现在的查找实际上是块操作,所以使用的是buffer
find之后:
total used free shared buffers cached
Mem: 3724 1713 2010 0 95 1246
[root@localhost ~]# vmstat
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
0 0 0 48584 118300 663564 0 0 12 23 60 240 3 2 95 0 0
procs:
r 正在运行或可运行的进程数,如果长期大于cpu个数,说明cpu不足,需要增加cpu
b block 但是这个是阻塞,表示在等待资源的进程数,比如正在等待I/O、或者内存交换等。 由于硬盘速度特别慢而导致内存同步的时候没成功,那么现在告诉程序,说你先不要产生数据,这就是阻塞
!!!!! ---> b越大证明硬盘压力很大
memory
swpd 切换到内存交换区的内存数量(k表示)。如果swpd的值不为0,或者比较大,比如超过了100m,只要si、so的值长期为0,系统性能还是正常
free 当前的空闲页面列表中内存数量(k表示)
buff 作为buffer cache的内存数量
cache: 作为page cache的内存数量
swap
si swapin 把swap分区的数据放到内存
so swapout 把内存数据放到磁盘
通过上面两个可以分析内存的使用情况,如果swap有数据是不是内存不够用了?不一定,因为系统会把一些用不到的进程放到swap里面,把腾出来的空间做缓存,如果发现si,so里面有数据,说明内存可能不够用了
IO
bi blockin 这个是块进来 ,把块儿从硬盘搬进来,也就是说bi是读
bo blockout 把块儿从内存搬到硬盘,也就是说bo是写
实验:
# vmstat -1
# dd if=/dev/zero of=/aa bs=1G count=1 //这条命令之后查看bo的数值,发现bo产生数据
记录了1+0 的读入
记录了1+0 的写出
1073741824字节(1.1 GB)已复制,4.90872 秒,219 MB/秒
#find / //这条命令之后查看bi,发现bi产生数据
如果 一直开着vmstat发现bo 5秒钟一个数,这就是因为脏数据5秒钟一次
如果要拿这个数据做图,bo的第一个数据一定要剔除到,这个数字是上一次重启到敲vmstat这条命令之间的平均值,所以这个数字没用
system 显示采集间隔内发生的中断数
in 列表示在某一时间间隔中观测到的每秒设备中断数。
cs列表示每秒产生的上下文切换次数
cpu:
剩下的就是cpu的各种使用百分比
以上解释都可以查看man手册:#man vmstat
========================================
buffer/cache
根据时间和数据大小同步 主要用于写缓存
内核里面的一套系统:伙伴系统,负责把内存里面的数据往硬盘上搬
rhel5:
kswapd pdflush
kswapd负责说什么时候搬数据
pdflush负责干活儿,他会一直开启着
rhel6:
kswapd负责说什么时候搬数据,但是干活儿的不是pdflush了
有需要搬的数据的时候,才产生一个进程---> flush 主设备号:从设备号 负责搬数据
已经同步到硬盘的数据就是干净数据
# cat /proc/sys/vm/dirty_ 查看的是脏数据(缓存内还没来得急同步到硬盘的数据)
dirty_background_bytes dirty_expire_centisecs
dirty_background_ratio dirty_ratio
dirty_bytes dirty_writeback_centisecs
[root@localhost ~]# cat /proc/sys/vm/dirty_expire_centisecs //想知道这里面是什么可以使用下面的man或者kernel-doc查看
2999 //单位百分之一秒,这里也就是30秒,30秒之后标记为脏数据,意味着用户写的数据在30秒之后才有可能被刷入磁盘,在这期间断电可能会丢数据
[root@localhost ~]# cat /proc/sys/vm/dirty_writeback_centisecs
499 // 5秒钟往硬盘同步一次数据5秒同步一次脏数据(在缓存中的)
假如我内存1G
1秒 100M
2秒 300M
3秒 400M
4秒 400M
还没到5秒,但是内存使用已经超过1G了,这时候怎么办?下面的文件来解决
[root@localhost ~]# cat /proc/sys/vm/dirty_ratio
40 //如果单个进程占用的buffer/cache达到内存总量的40%,立刻同步。
假如我内存1G,一个进程
1秒 1M
2秒 3M
3秒 4M
4秒 40M
那要是1000个进程呢?这时候怎么办?下面的文件来解决
[root@localhost ~]# cat /proc/sys/vm/dirty_background_ratio
10 //所有进程占用的buffer/cache使得剩余内存低于内存总量的10%,立刻同步
# cat /proc/sys/vm/dirty_background_bytes //上面的ratio文件用百分比,这个用字节限制,但是百分比存在的时候,字节不生效
0
如果服务器是一个数据服务器,比如NAS,dirty_writeback和dirty_ratio里面的数值可以适当改大一点,存储需要频繁读数据的时候,可以直接从内存里面读,而且在同步数据的时候会使用更大的连续的块儿。
=============================================
释放buffer/cache
[root@localhost ~]# cat /proc/sys/vm/drop_caches
0
1 释放buffer
2 释放cache
3 buffer/cache都释放
需要编译安装一个程序,在make的时候报错内存不足,这时候就可以释放一下缓存,一般情况下不要用
# watch -n 0.5 free -m
# echo 3 > /proc/sys/vm/drop_caches
=============================
内存如果真耗尽了,后果无法预测
OOM进程 OOM killer
out
当内存耗尽的时候,系统会出现一个OOM killer进程在系统内随机杀进程
每个运行的程序都会有一个score(分),这个是不良得分,所以谁分高,就杀谁
如果还不行的话,他会自杀,也就是杀kernel,就会出现内核恐慌(panic),所以会死机
实验:
#cat
# ps -el | grep cat
0 S 0 9566 2975 0 80 0 - 25232 n_tty_ pts/1 00:00:00 cat
# cat /proc/9566/oom_score
1
# cat /proc/9566/oom_adj
0 可以用这个值干预上面oom得分
-17 15 -17免杀,15是先干掉
# echo 15 > /proc/9566/oom_adj
# echo f > /proc/sysrq-trigger //启动OOM_KILLER 必杀一个
# cat //因为上面已经把9566的adj改成了15,所以这次启动杀死了cat进程
已杀死
swap
那么到底怎么解决内存耗尽的问题?swap
假如a,b,c已经把内存占满了,那么来了个d,内核先看看abc谁不忙,就把谁的数据先放到swap里面去,比如a不用,把a的数据放到swap里面去,释放出来的空间给d
swap分区分多大?现在内存很大比如256G,那么就没必要2倍了。。。
什么样的数据才能往swap里面放?
# cat /proc/meminfo | grep -i active
Active: 233836 kB
Inactive: 1280348 kB
Active(anon): 138780 kB
Inactive(anon): 26740 kB
Active(file): 95056 kB
Inactive(file): 1253608 kB
active活跃数据,inactive非活跃数据,又分为匿名数据和文件数据
匿名数据不能往swap里面放
文件形式的active不能往swap里放,只有文件的inactive才能往swap放
所以并不是有了swap,内存就解决了
什么时候放进去?根据swap_tendency(swap趋势)
swap_tendency = mapped_ratio/2 + distress + vm_swappiness
这就是swap趋势,如果这个值到达100,就往交换分区里面放,如果小于100,尽量不往里面放,但是就算到100,也只能说内核倾向与要往swap里面放,但也不一定放
系统就只开放第三个给用户设置
# cat /proc/sys/vm/swappiness swap的喜好程度,范围0-100
60
=============================
使用内存文件系统
#df -h
tmpfs 1.9G 224K 1.9G 1% /dev/shm (共享内存)
tmpfs 内存里面的临时文件系统 系统会承诺拿出50%(这里是2G)的空间来做SHM,只是承诺,实际用多少给多少,如果内存比较富裕的情况下,我们可以拿内存当硬盘使用
#mount -t tmpfs -o size=1000M tmpfs /mnt //挂内存
#dd if=/dev/zero of=/mnt/file1 bs=1M count=800
记录了800+0 的读入
记录了800+0 的写出
838860800字节(839 MB)已复制,0.310507 秒,2.7 GB/秒 //这里用的是内存的速度
# dd if=/dev/zero of=/tmp/file1 bs=1M count=800 oflag=direct
记录了800+0 的读入
记录了800+0 的写出
838860800字节(839 MB)已复制,8.77251 秒,95.6 MB/秒 //这里用的是硬盘的速度
如果临时对某一个目录有较高的io需求,可以使用上面的方法使用内存
----------------------------------------------------------------------------------------------
# mount -t tmpfs -o size=20000M tmpfs /mnt //发现这样也可以,为什么,这只是承诺给20G,并没有实际给20G
#dd if=/dev/zero of=/mnt/file1 //不指定多大,把swap关闭(如果不关会等半天),这样就会把内存耗尽,
========================
虚拟内存和物理内存
查看:
#top
VIRT RES SHR
虚拟内存:
应用程序没办法直接使用物理内存,每个程序都有一个被内核分配给自己的虚拟内存
虚拟内存申请:
32位CPU,2^32也就是4G
64位cpu,2^64
每个程序都最多能申请4G的虚拟内存,但是现在这4G内存还和物理内存没关系呢,a说我先用100M,然后内核就会把100M映射给物理内存
VIRT就是程序运行的时候说申请的虚拟内存,RES就是映射的内存
为什么要有虚拟内存?
跟开发有关系,内存是有地址空间的,开发者在调用内存的时候如果直接调用物理内存,开发者不知道哪块儿地址被占用了,所以在中间内核站出来给开发者分配,开发者只需要提出需要多大内存,由内核来解决你的内存就可以了
------------
程序1 程序2
4G 4G
-----------
kernel
-----------
物理内存
-----------
以上3层,第一层就是程序可以使用的虚拟内存,程序可以跟内核申请需要多少内存,内核就分配相应大小的物理内存给程序就可以了
========================
映射表:
概念:
内存是分页的,1个page是4k(默认值),在硬盘上分块,硬盘数据和内存数据是一一对应
问题:
条目非常多,查询特别慢
解决:
固有方法:
硬件TLB ,在cpu里面,用来解决查询映射表慢的问题,第一次查询过之后把结果缓存到TLB里面,以后再查的时候就可以直接从TLB里面提取
# yum install x86info
# x86info -a 可以查询TLB信息
自定义方法:
如果page变大,条目就会变少,这样就会提高查询速度
大于4k的分页称为hugepage 巨页 ,但是这个需要程序支持
那我们现在的操作系统是否支持巨页
# cat /proc/meminfo | grep -i hugepage
AnonHugePages: 26624 kB
HugePages_Total: 0 我现在没有巨页
HugePages_Free: 0
HugePages_Rsvd: 0
HugePages_Surp: 0
Hugepagesize: 2048 kB 说明现在我的系统支持2M的巨页
假如一个程序需要200M的巨页,那么就要把total改成100
#echo 100 > /proc/sys/vm/nr_hugepages //修改巨页total数目
#mkdir dir1
#mount -t hugetlbfs none /dir1 那么现在程序使用/dir1就可以了
外翻:
TLB(Translation Lookaside Buffer)传输后备缓冲器是一个内存管理单元用于改进虚拟地址到物理地址转换速度的缓存。TLB是一个小的,虚拟寻址的缓存,其中每一行都保存着一个由单个PTE组成的块。如果没有TLB,则每次取数据都需要两次访问内存,即查页表获得物理地址和取数据
========================
进程间通信(IPC)
种类:
进程间通信的方式有5种:
1.管道(pipe) 本地进程间通信,用来连接不同进程之间的数据流
2.socket 网络进程间通信,套接字(Socket)是由Berkeley在BSD系统中引入的一种基于连接的IPC,是对网络接口(硬件)和网络协议(软件)的抽象。它既解决了无名管道只能在相关进程间单向通信的问题,又解决了网络上不同主机之间无法通信的问题。
以上两种unix遗留下来的
3.消息队列(Message Queues) 消息队列保存在内核中,是一个由消息组成的链表。
4.共享内存段(Shared Memory) 共享内存允许两个或多个进程共享一定的存储区,因为不需要拷贝数据,所以这是最快的一种IPC。
5.信号量集(Semaphore Arrays) System V的信号量集表示的是一个或多个信号量的集合。
查看:
ipc 进程间通信
#ipcs //这条命令可以看到后3种,前两种可以通过文件类型查看
含义:
管道
a | b
在内存打开一个缓冲区,a把结果存到缓冲区,b去缓冲区里面拿数据
管道通信的时候 独木桥:特点-->只能一个人 单向 先进先出
3个人过桥,一个一个的过,那如果100个人过,速度会很慢,所以管道传输的数据有限
socket
IE浏览器 访问网站 通过端口 端口在系统内实际不存在是个伪概念,只是一个标识,
a会打开一个buffer b会打开一个buffer ,这两个buffer用来接受数据包,并且重组,交给apache的socket,apache就会去socket接受数据
消息队列
跟管道基本一样 也是独木桥,也是单向,先进先出,但是他会对消息进程排队,谁着急谁先走,那么过河的人多了之后,同样也是数据传输较慢
共享内存段
开辟一块内存,a把数据全都丢到共享内存里面,b去共享内存拿数据,而且b可以按需选择拿哪些数据
共享内存段在oracle里面肯定要使用
信号量
在a和b之间传递信号,a把一个文件锁住给b发一个信号,说这个文件我正在使用
信号所携带的数据量非常有限,只能指定信号是干什么用的
==============================================
查看内存使用情况
[root@localhost ~]# sar -r 1 1
01时31分38秒 kbmemfree kbmemused %memused kbbuffers kbcached kbcommit %commit
01时31分39秒 6045368 1917916 24.08 67236 649020 2435764 17.73
kbcommit:保证当前系统所需要的内存,即为了确保不溢出而需要的内存(RAM+swap).
%commit:这个值是kbcommit与内存总量(包括swap)的一个百分比.
I/O
I/O
这块是影响系统性能比较大的地方
查看速度:
#hdparm -t /dev/sda
影响I/O性能的因素
1.mount
2.文件系统:日志文件系统和非日志文件系统
3.I/O调度算法
4.RAID,LVM(条带化) 网络附加存储(cpu的iowait转移到存储服务器)mount
rw ro
atime noatime
Update inode access time for each access. This is the default.
atime是这里影响性能的一个重要因素,可以用noatime关掉
async、sync
[root@node1 ~]# mount /dev/sdb1 /mnt/
[root@node1 ~]# mount -o remount,sync /dev/sdb1 /mnt/
数据传输3种:
sync 应用程序产生数据也是写到缓存,但是会等到缓存内的脏数据同步到硬盘之后才会产生新的数据
async 应用程序把数据写到缓存,操作系统通过伙伴程序kswapd把脏数据写到硬盘,而且会一直产生脏数据,不会等
directIO直接IO 不会经过缓存,直接往硬盘上写
练习:
使用dd命令测试sync async directIO三种方式谁快谁慢
那么上面3种方式,对应用程序来说,async最快,其次是直接IO,最慢的是同步
问题:
虽然异步对应用程序快了,但是会产生问题,比如脏数据还没来得及全部同步到硬盘,突然断电了,这时候我们称硬盘上的不完整数据被损坏,或者数据不一致
解决:
断电我们阻止不了,但是我们可以重新写数据,但是现在他怎么知道哪个数据坏了?开机启动的时候使用fsck检测坏块儿问题:
但是fsck在数据量比较大的时候会非常慢,那怎么解决这个问题?
解决:
通过Journal日志 在数据写到内存之前先记录一下日志,如果断电重启之后发现哪个写操作没有完成,就通过日志恢复哪个就可以了
有日志以后的数据存储过程:
写日志
写数据
删除日志
ext4可以关掉日志,但是只有在格式化的时候才能关
有日志的话,会变慢,那这个问题如何解决?
创建2个分区,分别格式化为ext2、ext3,dd文件测试速度差异
记录日志的方法:
#man mount
Mount options for ext3
data={journal|ordered|writeback} journal最好,但是这种开销最大
journal 把信息写到缓存,记录日志,记录inode和数据到日志,然后写到硬盘
ordered 这是默认的模式把信息写到缓存,记录日志,只记录inode,然后写到硬盘
writeback首先在缓存内把所有的写排好序,然后记录inode,最后写到硬盘
性能上ordered和writeback差不多
解决记录日志慢问题:
之所以日志慢:硬盘是一个一个的磁盘片,硬盘效率最高的时候是磁头在某一个磁道不换位置,如果数据不连续也就意味着磁头要来回在日志数据所在的磁道和数据所在的磁道跳换,如果能解决这个问题就OK了。我们可以采用日志分离的方式
日志分离:
两块硬盘,一块存日志,一块存数据,必须是两块磁盘,两个分区是不可以的
#mke2fs -O journal_dev /dev/sdb5 //把这个设备格式化成专门记录日志的设备
#mkfs.ext3 -J device=/dev/sdb5 /dev/sdb1 //在格式化sdb1的时候声明日志记录在sdb5上,因为是做实验,这里用的是分区
#mount -o data=journal /dev/sdb1 /mnt/
在工作当中一般不用日志分离,因为一般我们的服务器上都是raid,所以速度不会慢到哪去,如果不用raid的设备就可能要用到日志分离
各种日志文件系统:
ext3
ext4
jfs IBM的 恢复相当快
xfs 处理大文件性能特别好
reiserfs suse用的文件系统
btresfs 处理小文件速度特别快
zfs z是26个英文字母的最后一个,寓意在他之后不会再有其他文件系统
rhel7已经放弃ext4了,使用xfs
I/O调度算法
查看调度算法
[root@localhost ~]# cat /sys/block/sda/queue/scheduler
noop anticipatory deadline [cfq] //这里是所有的算法,被中括号扩起来的cfq就是默认的调度算法
CFQ (Completely Fair Queuing 完全公平的排队)(elevator=cfq):
这是默认算法,对于通用服务器来说通常是最好的选择。它试图均匀地分布对I/O带宽的访问。在多媒体应用, 总能保证audio、video及时从磁盘读取数据。但对于其他各类应用表现也很好。每个进程一个queue,每个queue按照上述规则进行merge 和sort。进程之间round robin调度,每次执行一个进程的4个请求。
Deadline (elevator=deadline):
这个算法试图把每次请求的延迟降至最低。该算法重排了请求的顺序来提高性能。
NOOP (elevator=noop):
这个算法实现了一个简单FIFO队列。他假定I/O请求由驱动程序或者设备做了优化或者重排了顺序(就像一个智能控制器完成的工作那样)。在有些SAN环境下,这个选择可能是最好选择。适用于随机存取设备, no seek cost,非机械可随机寻址的磁盘。
Anticipatory (elevator=as):
这个算法推迟I/O请求,希望能对它们进行排序,获得最高的效率。同deadline不同之处在于每次处理完读请求之后, 不是立即返回, 而是等待几个微妙在这段时间内, 任何来自临近区域的请求都被立即执行. 超时以后, 继续原来的处理.基于下面的假设: 几个微妙内, 程序有很大机会提交另一次请求.调度器跟踪每个进程的io读写统计信息, 以获得最佳预期.
-------------------------------------
APP
app发出请求到下层
buffer cache
io调度器
硬盘
cfq 完全公平队列
a,b,c三个app发出请求, cfq会为每个app准备一个队列,cfg会在每个队列里面一次取4个请求,如果还有剩余请求,继续再取,总之是4个4个的取,他的好处就是每个app都会得到响应
每个app自己的请求可能都是连续的,但是app和app之间他们可能就不会在同一个磁道上,这样就会增加磁头的寻址
所以cfg适用于多媒体或者说桌面级系统
deadline
deadline会把a,b,c的所有请求放到同一个队列,然后对他们进行排序,然后在把统一类型的请求比如读的请求放到fifo里面(fifo就是先进先出)
比如:
a 11 12 13 47
b 31 32 38 39
c 27 28 41 42
deadline
11
12
13
27
28
31
32
38
39
41
42
47
先处理11,然后12,13,。。。。直到最后的47
但是deadline会使a进入饿死状态(比如47),怎样解决 我们会给每一个请求规定一个时间(过了这个时间就饿死了),如果发现某一个请求到时间了,那么停止现在其他所有的操作去处理到达规定时间的那个请求
11
12
13
27
28
31
32
38
39
41
42
47
anticipatory跟deadline差不多,3.0的内核里面已经砍掉了,但是跟deadline不一样的地方是处理11,12,13完事儿之后先等一下,看还有没有14,15如果没有的话再继续
noop直接fifo,谁先来,先处理谁 ssd的硬盘会使用 san存储也会用到
--------------------------------------------------------------------
对IO调度使用的建议
Deadline I/O scheduler 使用轮询的调度器,简洁小巧,提供了最小的读取延迟和尚佳的吞吐量,特别适合于读取较多的环境(比如数据库,Oracle 10G 之类).
Anticipatory I/O scheduler 假设一个块设备只有一个物理查找磁头(例如一个单独的SATA硬盘),将多个随机的小写入流合并成一个大写入流,用写入延时换取最大的写入吞吐量.适用于大多数环境,特别是写入较多的环境(比如文件服务器)Web,App等应用我们可以采纳as调度.
CFQ I/O scheduler使用QoS策略为所有任务分配等量的带宽,避免进程被饿死并实现了较低的延迟,可以认为是上述两种调度器的折中.适用于有大量进程的多用户系统
设置调度方法:
linux启动时设置默认IO调度,让系统启动时就使用默认的IO方法,只需在grub.conf文件中加入类似如下行
kernel /vmlinuz-2.6.24 ro root=/dev/sda1 elevator=deadline查看I/O状态
[root@localhost ~]# sar -d 1 100
Linux 2.6.32-358.el6.x86_64 (mail.robin.com) 2013年11月21日 _x86_64_ (1 CPU)
22时25分22秒 DEV tps rd_sec/s wr_sec/s avgrq-sz avgqu-sz await svctm %util
22时25分23秒 dev11-0 0.00 0.00 0.00 0.00 0.00 0.00 0.00 0.00
22时25分23秒 dev8-0 844.58 0.00 10987.95 13.01 0.54 0.65 0.48 40.84
时间 设备主从号 每秒读写请求次数 每秒读多少个扇区 每秒写的扇区个数 平均请求大小 平均队列长度 等待时间
tps 每秒请求数
rd_sec/s 每秒读的扇区数
wr_sec/s 每秒写的扇区数
avgrq-sz 平均每个请求的大小(读写)
avgqu-sz 平均队列长度 队列越长io性能越低
await io请求消耗的平均时间(毫秒) 所有时间(包括等待时间和服务时间)
await-svctm=io的等待时间 差值越大 io越繁忙
等待时间:假如现在有块硬盘,处理速度每秒能处理10个请求,那么我现在给他发15个,处理不过来怎么办?排队 await就是从进队列一直到处理完一共用了多长时间
svctm:调度器处理这个排队的请求用了多长时间,比如你排队看医生,医生给你看病花了多长时间
%util io处理io请求所消耗的cpu百分比
[root@localhost ~]# iostat -k
Device: tps kB_read/s kB_wrtn/s kB_read kB_wrtn
scd0 0.00 0.02 0.00 216 0
sda 653.44 28.39 4613.55 365863 59445489
[root@localhost ~]# iostat -x 1
Device: rrqm/s wrqm/s r/s w/s rsec/s wsec/s avgrq-sz avgqu-sz await svctm %util
scd0 0.00 0.00 0.00 0.00 0.03 0.00 6.86 0.00 2.76 2.76 0.00
sda 2.46 500.26 0.82 651.74 56.41 9215.99 14.21 0.69 1.06 0.73 47.67
rrqm/s 每秒合并的读请求次数
wrqm/s 每秒合并的写请求次数
a对某一个块发出一个读请求,但是现在因为硬盘速度慢,还没来得及处理,结果a又对这个块发出一个读请求,这样我们就可以把这两个读请求合并到一起
a对某一个块发出一个写请求,比如把某一块数据改成123,但是没来得及处理,a又对这个块儿发出一个写请求要把数据改成789,那么这个最后的结果是789,所以我们可以把这两个写请求合并
filesystem(了解)
需要一些编译工具,安装“开发工具” “开发库”
[root@localhost ~]# yum groupinstall "Development Libraries" "Development Tools"
安装与现有内核版本相对应的src.rpm
[root@localhost ~]# uname -r
2.6.18-308.el5xen
[root@localhost ~]# rpm -ivh /tmp/kernel-2.6.18-308.el5.src.rpm
rhel5会将src .rpm释放到/usr/src/redhat/中(rhel6会释放到当前用户家目录下的rpmbuild)
[root@localhost ~]# cd /usr/src/redhat/
[root@localhost redhat]# ls
BUILD RPMS SOURCES SPECS SRPMS
BUILD 操作源码过程中产生的数据
RPMS 存放制作好的rpm
SOURCES 存放程序的源代码和相关文件
SPECS 存放制作rpm所使用的spec脚本
SRPMS 存放src.rpm
[root@localhost redhat]# cd SPECS/
[root@localhost SPECS]# ls -l
总计 820
-rw-r--r-- 1 root root 834836 2010-03-17 kernel-2.6.spec
[root@localhost SPECS]# rpmbuild -bp --target=$(uname -m) kernel-2.6.spec
[root@localhost ~]# cd /usr/src/redhat/BUILD/kernel-2.6.18/linux-2.6.18.i686
[root@localhost linux-2.6.18.i686]# cp /boot/config-2.6.18-308.el5xen .config
编辑Makefile,EXTRAVERSION = -308.el5xen 与当前内核版本相对应
[root@localhost linux-2.6.18.i686]# vim Makefile
EXTRAVERSION = -308.el5xen #第四行
[root@localhost linux-2.6.18.i686]# make oldconfig
在编译模块的过程中需要 .tmp_versions临时目录
[root@localhost linux-2.6.18.i686]# mkdir .tmp_versions
在字符菜单中找到文件系统文件系统,在其中找到Reiserfs、JFS、XFS,使用M选中(ext4默认就已经有了)
[root@localhost linux-2.6.18.i686]# make menuconfig
File systems --->
<M> Reiserfs support
<M> JFS filesystem support
<M> XFS filesystem support
单独编译3个文件系统模块
[root@localhost linux-2.6.18.i686]# make fs/xfs/xfs.ko
[root@localhost linux-2.6.18.i686]# make fs/jfs/jfs.ko
[root@localhost linux-2.6.18.i686]# make fs/reiserfs/reiserfs.ko
在系统内核模块目录中,创建3个文件系统的对应目录,并将编译好的模块拷贝到对应的目录中
[root@localhost linux-2.6.18.i686]# mkdir /lib/modules/2.6.18-308.el5xen/kernel/fs/jfs
[root@localhost linux-2.6.18.i686]# mkdir /lib/modules/2.6.18-308.el5xen/kernel/fs/reiserfs
[root@localhost linux-2.6.18.i686]# mkdir /lib/modules/2.6.18-308.el5xen/kernel/fs/xfs
[root@localhost linux-2.6.18.i686]# cp fs/jfs/jfs.ko /lib/modules/2.6.18-308.el5xen/kernel/fs/jfs
[root@localhost linux-2.6.18.i686]# cp fs/reiserfs/reiserfs.ko /lib/modules/2.6.18-308.el5xen/kernel/fs/reiserfs
[root@localhost linux-2.6.18.i686]# cp fs/xfs/xfs.ko /lib/modules/2.6.18-308.el5xen/kernel/fs/xfs
ext4的模块rhel5u8中默认就有,放在以下位置
[root@localhost linux-2.6.18.i686]# ls /lib/modules/2.6.18-194.el5/kernel/fs/ext4/ext4.ko
/lib/modules/2.6.18-194.el5/kernel/fs/ext4/ext4.ko
检查模块依赖性并加载模块
[root@lcoalhost linux-2.6.18.i686]# depmod -a
[root@lcoalhost linux-2.6.18.i686]# modprobe xfs
[root@localhost linux-2.6.18.i686]# modprobe jfs
[root@localhost linux-2.6.18.i686]# modprobe reiserfs
[root@localhost linux-2.6.18.i686]# modprobe ext4
安装创建文件系统的工具
ext4:
[root@localhost tmp]# yum install e4fsprogs
JFS:
[root@localhost tmp]# tar xf jfsutils-1.1.14.tar.gz
./configure && make && make install
XFS:
[root@localhost tmp]# tar xf xfsprogs_2.9.8-1.tar.bz2
./configure && make && make install
REISERFS:
[root@localhost tmp]# tar xf reiserfsprogs-3.6.21.tar.bz2
./configure && make && make install
创建4个分区每个2G,分别给4个分区创建4种文件系统,并挂载到对应名称的目录
[root@localhost tmp]# mkfs.xfs /dev/sda13
[root@localhost tmp]# mkfs.jfs /dev/sda12
[root@localhost tmp]# mkreiserfs /dev/sda11
[root@localhost tmp]# mkfs.ext4 /dev/sda10
[root@localhost tmp]# mkdir /xfs
[root@localhost tmp]# mkdir /jfs
[root@localhost tmp]# mkdir /reiserfs
[root@localhost tmp]# mkdir /ext4
[root@localhost tmp]# mount -t xfs /dev/sda13 /xfs
[root@localhost tmp]# mount -t reiserfs /dev/sda11 /reiserfs/
[root@localhost tmp]# mount -t jfs /dev/sda12 /jfs/
[root@localhost tmp]# mount -t ext4 /dev/sda10 /ext4
[root@apache xfsprogs-2.9.8]# df -T
文件系统 类型 1K-块 已用 可用 已用% 挂载点
/dev/sda13 xfs 1949656 4256 1945400 1% /xfs
/dev/sda11 reiserfs 1959808 32840 1926968 2% /reiserfs
/dev/sda12 jfs 1951440 372 1951068 1% /jfs
/dev/sda10 ext4 1929068 35648 1795428 2% /ext4xfs(了解)
XFS 最初是由 Silicon Graphics,Inc. 开发的。支持最大文件系统到16EB,最大文件8EB,那数以千万计的目录结构条目。XFS文件系统支持metadata 日志,更快的崩溃恢复,在线整理碎片,在线增长,使用实用工具(xfsdump和xfsrestore)备份与恢复。xfs在处理特大文件上有很好的表现,在多线程并行I/O的工作模式下处理小文件也有很好的表现
xfs也支持以下特征
基于Extent的分配方式
XFS文件系统中的文件用到的块由变长Extent管理,每一个Extent描述了一个或多个连续的块。相比将每个文件用到的所有的块存储为列表的文件系统,这种策略大幅缩短了列表的长度。有些文件系统用一个或多个面向块的栅格管理空间分配在XFS中这种结构被由一对B+树组成的、面向Extent的结构替代了;每个文件系统分配组(AG)包含这样的一个结构。其中,一个B+树用于索引未被使用的Extent的长度,另一个索引这些Extent的起始块。这种双索引策略使得文件系统在定位剩余空间中的Extent时十分高效。
条带化分配
在条带化RAID阵列上创建XFS文件系统时,可以指定一个“条带化数据单元”。这可以保证数据分配、inode分配、以及内部日志被对齐到该条带单元上,以此最大化吞吐量。
延迟分配
XFS在文件分配上使用了惰性计算技术。当一个文件被写入缓存时,XFS简单地在内存中对该文件保留合适数量的块,而不是立即对数据分配Extent。实际的块分配仅在这段数据被冲刷到磁盘时才发生。这一机制提高了将这一文件写入一组连续的块中的机会,减少碎片的同时提升了性能。
扩展属性
XFS通过实现扩展文件属性给文件提供了多个数据流,使文件可以被附加多个名/值对。文件名是一个最大长度为256字节的、以NULL字符结尾的可打印字符串,其它的关联值则可包含多达 64KB 的二进制数据。这些数据被进一步分入两个名字空间中,root和user。保存在root名字空间中的扩展属性只能被超级用户修改,user名字空间中的可以被任何对该文件拥有写权限的用户修改。扩展属性可以被添加到任意一种XFS inode上,包括符号链接、设备节点、目录,等等。可以使用 attr 这个命令行程序操作这些扩展属性。xfsdump 和 xfsrestore 工具在进行备份和恢复时会一同操作扩展属性,而其它的大多数备份系统则会忽略扩展属性。
XFS 支援 disk quota。
xfs局限性
1.XFS是一个单节点文件系统,如果需要多节点同时访问需要考虑使用GFS2文件系统
2.XFS支持16EB文件系统,而redhat仅支持100TB文件系统
3.XFS较少的适用在单线程元数据密集的工作负荷,在单线程创建删除巨大数量的小文件的工作负荷下,其他文件系统(ext4)表现的会更好一些
4.xfs文件在操作元数据时可能会使用2倍的ext4CPU资源,在CPU资源有限制的情况下可以研究使用不同文件系统
5.xfs更多适用的特大文件的系统快速存储,ext4在小文件的系统或系统存储带宽有限的情况下表现的更好
[root@node6 ~]# yum install xfsprogs -y
[root@node6 ~]# mkfs.xfs /dev/vdb1
meta-data=/dev/vdb1 isize=256 agcount=4, agsize=6016 blks
= sectsz=512 attr=2, projid32bit=0
data = bsize=4096 blocks=24064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal log bsize=4096 blocks=1200, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@node6 ~]# mkfs.xfs -l logdev=/dev/vdb2 /dev/vdb1 -f
meta-data=/dev/vdb1 isize=256 agcount=4, agsize=6016 blks
= sectsz=512 attr=2, projid32bit=0
data = bsize=4096 blocks=24064, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0
log =/dev/vdb2 bsize=4096 blocks=24576, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@node6 ~]# mount -o logdev=/dev/vdb2 /dev/vdb1 /xfs/
[root@node6 ~]# pvcreate /dev/vdb1 /dev/vdb2
[root@node6 ~]# vgcreate vgxfs /dev/vdb2 /dev/vdb1
[root@node6 ~]# lvcreate -l 25 -n lvxfs vgxfs
Logical volume "lvxfs" created
[root@node6 ~]# mkfs.xfs /dev/vgxfs/lvxfs
meta-data=/dev/vgxfs/lvxfs isize=256 agcount=4, agsize=6400 blks
= sectsz=512 attr=2, projid32bit=0
data = bsize=4096 blocks=25600, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal log bsize=4096 blocks=1200, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
[root@node6 ~]# mount /dev/vgxfs/lvxfs /xfs/
[root@node6 ~]# lvextend -l +100%FREE /dev/vgxfs/lvxfs
[root@node6 ~]# xfs_growfs /xfs/
meta-data=/dev/mapper/vgxfs-lvxfs isize=256 agcount=4, agsize=6400 blks
= sectsz=512 attr=2, projid32bit=0
data = bsize=4096 blocks=25600, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0
log =internal bsize=4096 blocks=1200, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
data blocks changed from 25600 to 47104
[root@node6 ~]# umount /xfs
[root@node6 ~]# xfs_repair /dev/vgxfs/lvxfs
[root@node6 ~]# mkfs.xfs -l logdev=/dev/vdb2 /dev/vdb1
[root@node6 ~]# mount -o logdev=/dev/vdb2 /dev/vdb1 /xfs
[root@node6 ~]# for FILE in file{0..3} ; do dd if=/dev/zero of=/xfs/${FILE} bs=4M count=100 & done
[root@node6 ~]# filefrag /xfs/file*
[root@node6 ~]# xfs_fsr -v
[root@node6 ~]# umount /xfs
[root@node6 ~]# xfs_repair -n -l /dev/vdb2 /dev/vdb1
Phase 1 - find and verify superblock...
Phase 2 - using external log on /dev/vdb2
- scan filesystem freespace and inode maps...
- found root inode chunk
Phase 3 - for each AG...
- scan (but don't clear) agi unlinked lists...
- process known inodes and perform inode discovery...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- process newly discovered inodes...
Phase 4 - check for duplicate blocks...
- setting up duplicate extent list...
- check for inodes claiming duplicate blocks...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
No modify flag set, skipping phase 5
Phase 6 - check inode connectivity...
- traversing filesystem ...
- traversal finished ...
- moving disconnected inodes to lost+found ...
Phase 7 - verify link counts...
No modify flag set, skipping filesystem flush and exiting.
[root@node6 ~]#
[root@node6 ~]# xfs_repair -l /dev/vdb2 /dev/vdb1
Phase 1 - find and verify superblock...
Phase 2 - using external log on /dev/vdb2
- zero log...
- scan filesystem freespace and inode maps...
- found root inode chunk
Phase 3 - for each AG...
- scan and clear agi unlinked lists...
- process known inodes and perform inode discovery...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
- process newly discovered inodes...
Phase 4 - check for duplicate blocks...
- setting up duplicate extent list...
- check for inodes claiming duplicate blocks...
- agno = 0
- agno = 1
- agno = 2
- agno = 3
Phase 5 - rebuild AG headers and trees...
- reset superblock...
Phase 6 - check inode connectivity...
- resetting contents of realtime bitmap and summary inodes
- traversing filesystem ...
- traversal finished ...
- moving disconnected inodes to lost+found ...
Phase 7 - verify and correct link counts...
done
[root@node6 ~]# mount -o logdev=/dev/vdb2 /dev/vdb1 /xfs
[root@node6 ~]# yum install xfsdump
[root@node6 ~]# xfsdump -L full -M dumpfile -l 0 - /xfs | xz > /tmp/xfs.$(date +%Y%m%d).0.xz
xfsdump: using file dump (drive_simple) strategy
xfsdump: version 3.0.4 (dump format 3.0) - Running single-threaded
xfsdump: level 0 dump of node6.uplooking.com:/xfs
xfsdump: dump date: Sat Sep 14 17:39:47 2013
xfsdump: session id: 75f91e6b-c0bc-4ad1-978b-e2ee5deb01d4
xfsdump: session label: "full"
xfsdump: ino map phase 1: constructing initial dump list
xfsdump: ino map phase 2: skipping (no pruning necessary)
xfsdump: ino map phase 3: skipping (only one dump stream)
xfsdump: ino map construction complete
xfsdump: estimated dump size: 1677743680 bytes
xfsdump: /var/lib/xfsdump/inventory created
xfsdump: creating dump session media file 0 (media 0, file 0)
xfsdump: dumping ino map
xfsdump: dumping directories
xfsdump: dumping non-directory files
xfsdump: ending media file
xfsdump: media file size 1678152296 bytes
xfsdump: dump size (non-dir files) : 1678101072 bytes
xfsdump: dump complete: 152 seconds elapsed
xfsdump: Dump Status: SUCCESS
[root@node6 ~]#
[root@node6 ~]# xfsdump -I
file system 0:
fs id: 467c218c-22b5-45bc-9b0e-cd5782be6e2e
session 0:
mount point: node6.uplooking.com:/xfs
device: node6.uplooking.com:/dev/vdb1
time: Sat Sep 14 17:39:47 2013
session label: "full"
session id: 75f91e6b-c0bc-4ad1-978b-e2ee5deb01d4
level: 0
resumed: NO
subtree: NO
streams: 1
stream 0:
pathname: stdio
start: ino 131 offset 0
end: ino 135 offset 0
interrupted: NO
media files: 1
media file 0:
mfile index: 0
mfile type: data
mfile size: 1678152296
mfile start: ino 131 offset 0
mfile end: ino 135 offset 0
media label: "dumpfile"
media id: de67b2b5-db72-4555-9804-a050829b2179
xfsdump: Dump Status: SUCCESS
[root@node6 ~]# rm -rf /xfs/*
[root@node6 ~]# xzcat /tmp/xfs.20130914.0.xz | xfsrestore - /xfs
xfsrestore: using file dump (drive_simple) strategy
xfsrestore: version 3.0.4 (dump format 3.0) - Running single-threaded
xfsrestore: searching media for dump
xfsrestore: examining media file 0
xfsrestore: dump description:
xfsrestore: hostname: node6.uplooking.com
xfsrestore: mount point: /xfs
xfsrestore: volume: /dev/vdb1
xfsrestore: session time: Sat Sep 14 17:39:47 2013
xfsrestore: level: 0
xfsrestore: session label: "full"
xfsrestore: media label: "dumpfile"
xfsrestore: file system id: 467c218c-22b5-45bc-9b0e-cd5782be6e2e
xfsrestore: session id: 75f91e6b-c0bc-4ad1-978b-e2ee5deb01d4
xfsrestore: media id: de67b2b5-db72-4555-9804-a050829b2179
xfsrestore: searching media for directory dump
xfsrestore: reading directories
xfsrestore: 1 directories and 4 entries processed
xfsrestore: directory post-processing
xfsrestore: restoring non-directory files
xfsrestore: restore complete: 33 seconds elapsed
xfsrestore: Restore Status: SUCCESS
[root@node6 ~]# ls /xfs
file0 file1 file2 file3net
一台服务器CPU和内存资源额定有限的情况下,如何提高服务器的性能是作为系统运维的重要工作。要提高Linux系统下的负载能力,当网站发展起来之后,web连接数过多的问题就会日益明显。在节省成本的情况下,可以考虑修改Linux 的内核TCP/IP参数来部分实现;
Linux系统下,TCP/IP连接断开后,会以TIME_WAIT状态保留一定的时间,然后才会释放端口。当并发请求过多的时候,就会产生大量的 TIME_WAIT状态的连接,无法及时断开的话,会占用大量的端口资源和服务器资源(因为关闭后进程才会退出)。这个时候我们可以考虑优化TCP/IP 的内核参数,来及时将TIME_WAIT状态的端口清理掉。
写在/etc/sysctl.conf里.开路由的也在这里.
net.ipv4.tcp_syncookies = 1 表示开启SYN Cookies。当出现SYN等待队列溢出时,启用cookies来处理,可防范少量SYN攻击,默认为0,表示关闭;
net.ipv4.tcp_tw_reuse = 1 表示开启重用。允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭;
net.ipv4.tcp_tw_recycle = 1 表示开启TCP连接中TIME-WAIT sockets的快速回收,默认为0,表示关闭;
net.ipv4.tcp_fin_timeout = 5 修改系统默认的 TIMEOUT 时间。
net.ipv4.tcp_timestamps = 1 以一种比重发超时更精确的方法(参阅 RFC 1323)来启用对 RTT 的计算;为了实现更好的性能应该启用这个选项
net.ipv4.tcp_keepalive_time = 1200 表示当keepalive起用的时候,TCP发送keepalive消息的频度。缺省是2小时,改为20分钟。
net.ipv4.ip_local_port_range = 10000 65000 表示用于向外连接的端口范围。缺省情况下很小:32768到61000,改为10000到65000。(注意:这里不要将最低值设的太低,否则可能会占用掉正常的端口!)
net.ipv4.tcp_max_syn_backlog = 8192 表示SYN队列的长度,默认为1024,加大队列长度为8192,可以容纳更多等待连接的网络连接数。
net.ipv4.tcp_max_tw_buckets = 5000 表示系统同时保持TIME_WAIT的最大数量,如果超过这个数字,TIME_WAIT将立刻被清除并打印警告信息。默认为180000,改为5000。对于Apache、Nginx等服务器,上几行的参数可以很好地减少TIME_WAIT套接字数量。
网卡绑定
网卡绑定
网卡绑定的分类
模式 7中
Ethernet Channel Bonding
Linux双网卡绑定的实现是使用两块网卡虚拟成为一块网卡,这个聚合起来的设备看起来是一个单独的以太网接口设备,通俗点讲就是两块网卡具有相同的IP地址而并行链接聚合成一个逻辑链路工作。其实这项技术在Sun和Cisco中早已存在,被称为Trunking和Etherchannel技术,在Linux的2.4.x以上内核中也采用这这种技术,被称为bonding。bonding技术的最早应用是在集群,为了提高集群节点间的数据传输而设计的。
bonding的配置方式文档
[root@localhost ~]# rpm -q kernel-doc
/usr/share/doc/kernel-doc-2.6.18/Documentation/networking/bonding.txt
系统是否支持bonding
# modinfo bonding
如果没有返回消息,说明不支持需要重新编译内核
检查ifenslave
#which ifenslave
/sbin/ifenslave
分别修改2个网卡配置文件,声明自己为slave,master是bond0
[root@localhost ~]# vim /etc/sysconfig/network-scripts/ifcfg-eth0
---
DEVICE=eth0
USERCTL=no
ONBOOT=yes
BOOTPROTO=none
MASTER=bond0
SLAVE=yes
---
生成master设备的配置文件
[root@localhost ~]# vim /etc/sysconfig/network-scripts/ifcfg-bond0
-----------
DEVICE=bond0
IPADDR=192.168.122.254
NETMASK=255.255.255.0
ONBOOT=yes
BOOTPROTO=none
USERCTL=no
-----------
bond0是什么设备?实际我们做的网卡绑定,是通过bonding模块来实现的,所以要bonding模块设置一个别名,指向我们创建的bond0
[root@localhost ~]# vim /etc/modprobe.conf
---
alias bond0 bonding
options bonding miimon=100 mode=balance-rr
options bond0 miimon=100 mode=1 primary=eth0 //模式为1的时候使用这行配置
RHEL6下不再有modprobe.conf这个文件
在/etc/modprobe.d/里建立bond0.conf
# cat /etc/modprobe.d/bond0.conf
alias bond0 bonding
---
miimon是用来进行链路监测的。 比如:miimon=100,那么系统每100ms监测一次链路连接状态,如果有一条线路不通就转入另一条线路;
mode的值表示工作模式,他共有0,1,2,3四种模式,常用的为0,1两种。
mode=0表示load balancing (round-robin)为负载均衡方式,两块网卡都工作。
mode=1表示fault-tolerance (active-backup)提供冗余功能,工作方式是主备的工作方式,也就是说默认情况下只有一块网卡工作,另一块做备份.
重启服务,如果不生效需要重启系统:
[root@localhost ~]# service network restart
验证bond0是否成功:
[root@localhost ~]# cat /proc/net/bonding/bond0
===================================
rhel6
DEVICE=bond0
IPADDR=192.168.0.253
NETMASK=255.255.255.0
ONBOOT=yes
NM_CONTROLLED=no
BOOTPROTO=none
USERCTL=no
BONDING_OPTS="miimon=50 mode=0"
建立bonding.conf
#cat /etc/modprobe.d/bond.conf
alias bond0 bonding
在/etc/rc.local文件末尾加入如下内容
#vi /etc/rc.local
ifenslave bond0 eth0 eth2资源控制
ulimit
系统性能一直是一个受关注的话题,如何通过最简单的设置来实现最有效的性能调优,如何在有限资源的条件下保证程序的运作,ulimit 是我们在处理这些问题时,经常使用的一种简单手段。ulimit 是一种 linux 系统的内键功能,它具有一套参数集,用于为由它生成的 shell 进程及其子进程的资源使用设置限制。
ulimit 功能简述
假设有这样一种情况,当一台 Linux 主机上同时登陆了 10 个人,在系统资源无限制的情况下,这 10 个用户同时打开了 500 个文档,而假设每个文档的大小有 10M,这时系统的内存资源就会受到巨大的挑战。
而实际应用的环境要比这种假设复杂的多,例如在一个嵌入式开发环境中,各方面的资源都是非常紧缺的,对于开启文件描述符的数量,分配堆栈的大小,CPU 时间,虚拟内存大小,等等,都有非常严格的要求。资源的合理限制和分配,不仅仅是保证系统可用性的必要条件,也与系统上软件运行的性能有着密不可分的联系。这时,ulimit 可以起到很大的作用,它是一种简单并且有效的实现资源限制的方式。
ulimit 用于限制 shell 启动进程所占用的资源,支持以下各种类型的限制:所创建的内核文件的大小、进程数据块的大小、Shell 进程创建文件的大小、内存锁住的大小、常驻内存集的大小、打开文件描述符的数量、分配堆栈的最大大小、CPU 时间、单个用户的最大线程数、Shell 进程所能使用的最大虚拟内存。同时,它支持硬资源和软资源的限制。
作为临时限制,ulimit 可以作用于通过使用其命令登录的 shell 会话,在会话终止时便结束限制,并不影响于其他 shell 会话。而对于长期的固定限制,ulimit 命令语句又可以被添加到由登录 shell 读取的文件中,作用于特定的 shell 用户。
[root@localhost Desktop]# ulimit -a
core file size (blocks, -c) 0 #最大的 core 文件的大小, 以 blocks 为单位
core文件的简单介绍
在一个程序崩溃时,它一般会在指定目录下生成一个core文件。core文件仅仅是一个内存映象(同时加上调试信息),主要是用来调试的。
data seg size (kbytes, -d) unlimited #进程最大的数据段的大小,以 Kbytes 为单位。
scheduling priority (-e) 0
file size (blocks, -f) unlimited #进程可以创建文件的最大值,以 blocks 为单位。
pending signals (-i) 59335
max locked memory (kbytes, -l) 64 #最大可加锁内存大小,以 Kbytes 为单位。
max memory size (kbytes, -m) unlimited #最大内存大小,以 Kbytes 为单位
open files (-n) 1024 #可以打开最大文件描述符的数量。
pipe size (512 bytes, -p) 8 #管道缓冲区的大小,以 512byte/个 为单位。
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 10240 #堆栈大小,以 Kbytes 为单位。
cpu time (seconds, -t) unlimited #最大的 CPU 占用时间,以秒为单位。
max user processes (-u) 59335 #用户最大可用的进程数。
virtual memory (kbytes, -v) unlimited #进程最大可用的虚拟内存,以 Kbytes 为单位。
file locks (-x) unlimited
-a 显示当前所有的 limit 信息。
-H 设置硬资源限制,一旦设置不能增加。 ulimit Hs 64;限制硬资源,线程栈大小为 64K。
-S 设置软资源限制,设置后可以增加,但是不能超过硬资源设置。 ulimit Sn 32;限制软资源,32 个文件描述符。
限制使用CPU时间
[root@localhost ~]# vim /tmp/a.sh
#!/bin/bash
while true
do
:
done
[root@localhost ~]# ulimit -t 20
[root@localhost ~]# ulimit -a | grep "cpu time"
cpu time (seconds, -t) 20
[root@localhost ~]# /tmp/a.sh
Killed
限制用户使用的虚拟内存
[root@localhost ~]# ulimit -v 0
[root@localhost ~]# ls
Killed
[root@localhost ~]# df
Killed
[root@localhost ~]# ps
Killed
[root@localhost ~]# cd /etc
[root@localhost etc]# echo 111
111
[root@localhost etc]# type cd
cd is a shell builtin
[root@localhost etc]# type echo
echo is a shell builtin
限制创建文件大小
[root@node5 ~]# ulimit -f 1000
[root@node5 ~]# dd if=/dev/zero of=file1 bs=1024 count=1001
File size limit exceeded (core dumped)
[root@node5 ~]# dd if=/dev/zero of=file1 bs=1024 count=900
900+0 records in
900+0 records out
921600 bytes (922 kB) copied, 0.0031932 s, 289 MB/s
系统性能一直是一个受关注的话题,如何通过最简单的设置来实现最有效的性能调优,如何在有限资源的条件下保证程序的运作,ulimit 是我们在处理这些问题时,经常使用的一种简单手段。ulimit 是一种 linux 系统的内键功能,它具有一套参数集,用于为由它生成的 shell 进程及其子进程的资源使用设置限制。
ulimit 功能简述
假设有这样一种情况,当一台 Linux 主机上同时登陆了 10 个人,在系统资源无限制的情况下,这 10 个用户同时打开了 500 个文档,而假设每个文档的大小有 10M,这时系统的内存资源就会受到巨大的挑战。
而实际应用的环境要比这种假设复杂的多,例如在一个嵌入式开发环境中,各方面的资源都是非常紧缺的,对于开启文件描述符的数量,分配堆栈的大小,CPU 时间,虚拟内存大小,等等,都有非常严格的要求。资源的合理限制和分配,不仅仅是保证系统可用性的必要条件,也与系统上软件运行的性能有着密不可分的联系。这时,ulimit 可以起到很大的作用,它是一种简单并且有效的实现资源限制的方式。
ulimit 用于限制 shell 启动进程所占用的资源,支持以下各种类型的限制:所创建的内核文件的大小、进程数据块的大小、Shell 进程创建文件的大小、内存锁住的大小、常驻内存集的大小、打开文件描述符的数量、分配堆栈的最大大小、CPU 时间、单个用户的最大线程数、Shell 进程所能使用的最大虚拟内存。同时,它支持硬资源和软资源的限制。
作为临时限制,ulimit 可以作用于通过使用其命令登录的 shell 会话,在会话终止时便结束限制,并不影响于其他 shell 会话。而对于长期的固定限制,ulimit 命令语句又可以被添加到由登录 shell 读取的文件中,作用于特定的 shell 用户。
[root@localhost Desktop]# ulimit -a
core file size (blocks, -c) 0 #最大的 core 文件的大小, 以 blocks 为单位
core文件的简单介绍
在一个程序崩溃时,它一般会在指定目录下生成一个core文件。core文件仅仅是一个内存映象(同时加上调试信息),主要是用来调试的。
data seg size (kbytes, -d) unlimited #进程最大的数据段的大小,以 Kbytes 为单位。
scheduling priority (-e) 0
file size (blocks, -f) unlimited #进程可以创建文件的最大值,以 blocks 为单位。
pending signals (-i) 59335
max locked memory (kbytes, -l) 64 #最大可加锁内存大小,以 Kbytes 为单位。
max memory size (kbytes, -m) unlimited #最大内存大小,以 Kbytes 为单位
open files (-n) 1024 #可以打开最大文件描述符的数量。
pipe size (512 bytes, -p) 8 #管道缓冲区的大小,以 512byte/个 为单位。
POSIX message queues (bytes, -q) 819200
real-time priority (-r) 0
stack size (kbytes, -s) 10240 #堆栈大小,以 Kbytes 为单位。
cpu time (seconds, -t) unlimited #最大的 CPU 占用时间,以秒为单位。
max user processes (-u) 59335 #用户最大可用的进程数。
virtual memory (kbytes, -v) unlimited #进程最大可用的虚拟内存,以 Kbytes 为单位。
file locks (-x) unlimited
-a 显示当前所有的 limit 信息。
-H 设置硬资源限制,一旦设置不能增加。 ulimit Hs 64;限制硬资源,线程栈大小为 64K。
-S 设置软资源限制,设置后可以增加,但是不能超过硬资源设置。 ulimit Sn 32;限制软资源,32 个文件描述符。
限制使用CPU时间
[root@localhost ~]# vim /tmp/a.sh
#!/bin/bash
while true
do
:
done
[root@localhost ~]# ulimit -t 20
[root@localhost ~]# ulimit -a | grep "cpu time"
cpu time (seconds, -t) 20
[root@localhost ~]# /tmp/a.sh
Killed
限制用户使用的虚拟内存
[root@localhost ~]# ulimit -v 0
[root@localhost ~]# ls
Killed
[root@localhost ~]# df
Killed
[root@localhost ~]# ps
Killed
[root@localhost ~]# cd /etc
[root@localhost etc]# echo 111
111
[root@localhost etc]# type cd
cd is a shell builtin
[root@localhost etc]# type echo
echo is a shell builtin
限制创建文件大小
[root@node5 ~]# ulimit -f 1000
[root@node5 ~]# dd if=/dev/zero of=file1 bs=1024 count=1001
File size limit exceeded (core dumped)
[root@node5 ~]# dd if=/dev/zero of=file1 bs=1024 count=900
900+0 records in
900+0 records out
921600 bytes (922 kB) copied, 0.0031932 s, 289 MB/s
pam_limit.so
pam_limits 资源限制模块(提供的管理组:session)
pam 插入式验证模块
为使用此模块, 系统管理员必须首先建立一个 root只读 的文件(默认是 /etc/security/limits.conf). 这文件描述了superuser想强迫用户和用户组的资源限制. uid=0的帐号不会受限制.
以下参数可以用来改变此模块的行为:
* debug - 往syslog(3)写入冗长的记录.
* conf=/path/to/file.conf - 指定一个替换的limits设定档.
设定档的每一行描述了一个用户的限制,以下面的格式:
<domain> <type> <item> <value>
上面列出的栏位可以填下面的值:...
<domain> 可以是:
* 一个用户名
* 一个组名,语法是@group
* 通配符*, 定义默认条目
<type> 可以有一下两个值:
* hard 为施行硬 资源限制. 这些限制由superuser设定,由Linux内核施行. 用户不能提升他对资源的需求到大于此值.
* soft 为施行软 资源限制. 用户的限制能在软硬限制之间上下浮动. 这种限制在普通用法下可以看成是默认值.
<item> 可以是以下之一:
* core - 限制core文件的大小(KB)
* data - 最大的资料大小 (KB)
* fsize - 最大的文件尺寸 (KB)
* memlock - 最大能锁定的内存空间(KB)
* nofile - 最多能打开的文件
* rss - 最大的驻留程序大小(KB)
* stack - 最大的堆栈尺寸(KB)
* cpu - 最大的CPU 时间(分钟)
* nproc - 最多的进程数
* as - 地址空间的限制
* maxlogins - 用户的最多登录数
* priority - 用户进程执行时的优先级
要完全不限制用户(或组), 可以用一个(-)(例如: ``bin -'', ``@admin -''). 注意,个体的限制比组限制的优先级高, 所以如果你设定admin组不受限制, 但是组中的某个成员被设定档中某行限制, 那么此用户就会依据这样被限制.还应该注意, 所有的限制设定只是每个登录的设定. 他们既不是全局的,也不是永久的 ; 之存在于会话期间.
pam_limits 模块会通过syslog(3)报告它从设定档中找到的问题.
下面配置文件实例:
# EXAMPLE /etc/security/limits.conf file:
# =======================================
# <domain> <type> <item> <value>
* soft core 0
* hard rss 10000
@student hard nproc 20
@faculty soft nproc 20
@faculty hard nproc 50
ftp hard nproc 0
注意, 对同一个资源的软限制和硬限制 - 这建立了用户可以从指定服务会话中得到的默认和最大允许的资源数.
限制用户登录次数
/etc/security/limits.conf
[root@localhost ~]# vim /etc/pam.d/login
session required pam_limits.so
[root@localhost ~]# vim /etc/security/limits.conf
hulk hard maxlogins 2
限制用户打开进程数
[root@localhost ~]# vim /etc/security/limits.conf
hulk hard nproc 3
[root@localhost ~]# useradd hulk
[root@localhost ~]# echo "123456" | passwd --stdin hulk
[root@localhost ~]# su - hulk
[hulk@localhost ~]$ sleep 3000 &
[1] 4650
[hulk@localhost ~]$ sleep 3000 &
[2] 4651
[hulk@localhost ~]$ sleep 3000 &
-bash: fork: retry: Resource temporarily unavailable
限制用户使用CPU时间
[root@localhost ~]# vim /etc/security/limits.conf
hulk hard cpu 1
[hulk@localhost ~]$ ./a.sh 脚本执行1分钟后
Killed
限制用户创建文件大小
[root@localhost ~]# vim /etc/security/limits.conf
hulk hard fsize 500
[root@localhost ~]# su - hulk
[hulk@localhost ~]$ dd if=/dev/zero of=file1 bs=1M count=1
File size limit exceeded (core dumped)
cgroup
Cgroups是什么?
Cgroups是control groups的缩写,是Linux内核提供的一种可以限制、记录、隔离进程组(process groups)所使用的物理资源(如:cpu,memory,IO等等)的机制。最初由google的工程师提出,后来被整合进Linux内核。Cgroups也是LXC为实现虚拟化所使用的资源管理手段,可以说没有cgroups就没有LXC。
概述LXC为LinuxContainer的简写。LinuxContainer容器是一种内核虚拟化技术,可以提供轻量级的虚拟化
Cgroups可以做什么?
Cgroups最初的目标是为资源管理提供的一个统一的框架,既整合现有的cpuset等子系统,也为未来开发新的子系统提供接口。现在的cgroups适用于多种应用场景,从单个进程的资源控制,到实现操作系统层次的虚拟化(OS Level Virtualization)。Cgroups提供了一下功能:
1.限制进程组可以使用的资源数量(Resource limiting )。比如:memory子系统可以为进程组设定一个memory使用上限,一旦进程组使用的内存达到限额再申请内存,就会出发OOM(out of memory)。
2.进程组的优先级控制(Prioritization )。比如:可以使用cpu子系统为某个进程组分配特定cpu share。
3.记录进程组使用的资源数量(Accounting )。比如:可以使用cpuacct子系统记录某个进程组使用的cpu时间
4.进程组隔离(Isolation)。比如:使用ns子系统可以使不同的进程组使用不同的namespace,以达到隔离的目的,不同的进程组有各自的进程、网络、文件系统挂载空间。
5.进程组控制(Control)。比如:使用freezer子系统可以将进程组挂起和恢复。
Cgroups相关概念及其关系
相关概念
1.任务(task)。在cgroups中,任务就是系统的一个进程。
2.控制族群(control group)。控制族群就是一组按照某种标准划分的进程。Cgroups中的资源控制都是以控制族群为单位实现。一个进程可以加入到某个控制族群,也从一个进程组迁移到另一个控制族群。一个进程组的进程可以使用cgroups以控制族群为单位分配的资源,同时受到cgroups以控制族群为单位设定的限制。
3.层级(hierarchy)。控制族群可以组织成hierarchical的形式,既一颗控制族群树。控制族群树上的子节点控制族群是父节点控制族群的孩子,继承父控制族群的特定的属性。
4.子系统(subsytem)。一个子系统就是一个资源控制器,比如cpu子系统就是控制cpu时间分配的一个控制器。子系统必须附加(attach)到一个层级上才能起作用,一个子系统附加到某个层级以后,这个层级上的所有控制族群都受到这个子系统的控制。
相互关系
1.每次在系统中创建新层级时,该系统中的所有任务都是那个层级的默认 cgroup(我们称之为 root cgroup ,此cgroup在创建层级时自动创建,后面在该层级中创建的cgroup都是此cgroup的后代)的初始成员。
2.一个子系统最多只能附加到一个层级。
3.一个层级可以附加多个子系统
4.一个任务可以是多个cgroup的成员,但是这些cgroup必须在不同的层级。
5.系统中的进程(任务)创建子进程(任务)时,该子任务自动成为其父进程所在 cgroup 的成员。然后可根据需要将该子任务移动到不同的 cgroup 中,但开始时它总是继承其父任务的cgroup。
Cgroups子系统介绍
blkio 这个子系统为块设备设定输入/输出限制,比如物理设备(磁盘,固态硬盘,USB 等等)。
cpu 这个子系统使用调度程序提供对 CPU 的 cgroup 任务访问。
cpuacct 这个子系统自动生成 cgroup 中任务所使用的 CPU 报告。
cpuset 这个子系统为 cgroup 中的任务分配独立 CPU(在多核系统)和内存节点。
devices 这个子系统可允许或者拒绝 cgroup 中的任务访问设备。
freezer 这个子系统挂起或者恢复 cgroup 中的任务。
memory 这个子系统设定 cgroup 中任务使用的内存限制,并自动生成由那些任务使用的内存资源报告。
net_cls 这个子系统使用等级识别符(classid)标记网络数据包,可允许 Linux 流量控制程序(tc)识别从具体 cgroup 中生成的数据包。
ns 名称空间子系统。
安装kernel-doc查看帮助
[root@localhost ~]# ls /usr/share/doc/kernel-doc-2.6.32/Documentation/cgroups/
00-INDEX cpuacct.txt freezer-subsystem.txt net_prio.txt
blkio-controller.txt cpusets.txt memcg_test.txt resource_counter.txt
cgroups.txt devices.txt memory.txt



