MySQL-Replication
MySQL Replication
主从复制(也称 AB 复制)允许将来自一个MySQL数据库服务器(主服务器)的数据复制到一个或多个MySQL数据库服务器(从服务器)。
复制是异步的 从站不需要永久连接以接收来自主站的更新。
根据配置,您可以复制数据库中的所有数据库,所选数据库甚至选定的表。
MySQL中复制的优点包括:
- 横向扩展解决方案 - 在多个从站之间分配负载以提高性能。在此环境中,所有写入和更新都必须在主服务器上进行。但是,读取可以在一个或多个从设备上进行。该模型可以提高写入性能(因为主设备专用于更新),同时显着提高了越来越多的从设备的读取速度。
- 数据安全性 - 因为数据被复制到从站,并且从站可以暂停复制过程,所以可以在从站上运行备份服务而不会破坏相应的主数据。
- 分析 - 可以在主服务器上创建实时数据,而信息分析可以在从服务器上进行,而不会影响主服务器的性能。
- 远程数据分发 - 您可以使用复制为远程站点创建数据的本地副本,而无需永久访问主服务器。
Replication的原理
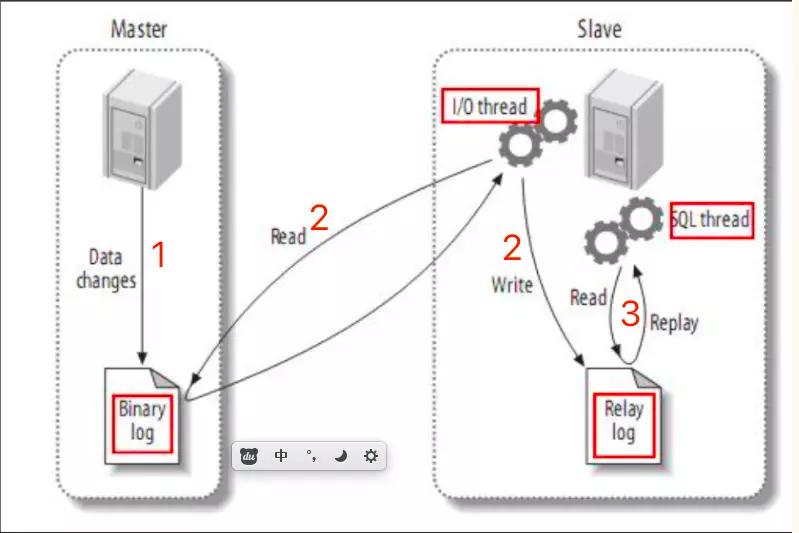
前提是作为主服务器角色的数据库服务器必须开启二进制日志
主服务器上面的任何修改都会通过自己的 I/O tread(I/O 线程)保存在二进制日志 Binary log 里面。
从服务器上面也启动一个 I/O thread,通过配置好的用户名和密码, 连接到主服务器上面请求读取二进制日志,然后把读取到的二进制日志写到本地的一个Realy log(中继日志)里面。
从服务器上面同时开启一个 SQL thread 定时检查 Realy log(这个文件也是二进制的),如果发现有更新立即把更新的内容在本机的数据库上面执行一遍。
每个从服务器都会收到主服务器二进制日志的全部内容的副本。
从服务器设备负责决定应该执行二进制日志中的哪些语句。
除非另行指定,否则主从二进制日志中的所有事件都在从站上执行。
如果需要,您可以将从服务器配置为仅处理一些特定数据库或表的事件。
重要: 您无法将主服务器配置为仅记录特定事件。
每个从站(从服务器)都会记录二进制日志坐标:
文件名
文件中它已经从主站读取和处理的位置。
由于每个从服务器都分别记录了自己当前处理二进制日志中的位置,因此可以断开从服务器的连接,重新连接然后恢复继续处理。
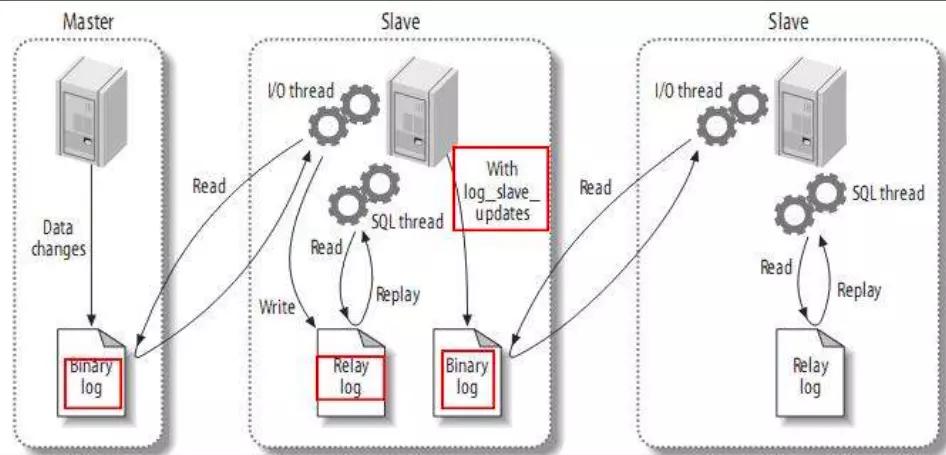
一主多从
如果一主多从的话,这时主库既要负责写又要负责为几个从库提供二进制日志。此时可以稍做调整,将二进制日志只给某一从,这一从再开启二进制日志并将自己的二进制日志再发给其它从。或者是干脆这个从不记录只负责将二进制日志转发给其它从,这样架构起来性能可能要好得多,而且数据之间的延时应该也稍微要好一些。工作原理图如下:
练习题:
使用三台机器搭建一主多从的mysql架构并能够实现数据同步, 部署形式不限<脚本、手动都可>关于二进制日志
mysqld将数字扩展名附加到二进制日志基本名称以生成二进制日志文件名。每次服务器创建新日志文件时,该数字都会增加,从而创建一系列有序的文件。每次启动或刷新日志时,服务器都会在系列中创建一个新文件。服务器还会在当前日志大小达到max_binlog_size参数设置的大小后自动创建新的二进制日志文件 。二进制日志文件可能会比max_binlog_size使用大型事务时更大, 因为事务是以一个部分写入文件,而不是在文件之间分割。
为了跟踪已使用的二进制日志文件, mysqld还创建了一个二进制日志索引文件,其中包含所有使用的二进制日志文件的名称。默认情况下,它具有与二进制日志文件相同的基本名称,并带有扩展名'.index'。在mysqld运行时,您不应手动编辑此文件。
术语二进制日志文件通常表示包含数据库事件的单个编号文件。
术语 二进制日志 表示含编号的二进制日志文件集加上索引文件。
SUPER 权限的用户可以使用SET sql_log_bin=0语句禁用其当前环境下自己的语句的二进制日志记录
配置Replication
配置步骤:
- 在主服务器上,您必须启用二进制日志记录并配置唯一的服务器ID。需要重启服务器。
编辑主服务器的配置文件 my.cnf,添加如下内容
[mysqld]
log-bin=/var/log/mysql/mysql-bin
server-id=1创建日志目录并赋予权限
[root@mysql ~]# mkdir /var/log/mysql
[root@mysql ~]# chown mysql.mysql /var/log/mysql重启服务
[root@mysql ~]# systemctl restart mysqld注意::
如果省略server-id(或将其显式设置为默认值0),则主服务器拒绝来自从服务器的任何连接。
为了在使用带事务的InnoDB进行复制设置时尽可能提高持久性和一致性,
您应该在master my.cnf文件中使用以下配置项:
innodb_flush_log_at_trx_commit = 1
sync_binlog = 1
确保未在复制主服务器上启用skip-networking选项。
如果已禁用网络,则从站无法与主站通信,并且复制失败。2.应该创建一个专门用于复制数据的用户
每个从服务器需要使用MySQL 主服务器上的用户名和密码连接到主站。
例如,计划使用用户 repl 可以从任何主机上连接到 master 上进行复制操作, 并且用户 repl 仅可以使用复制的权限。
在 主服务器 上执行如下操作
mysql> CREATE USER 'repl'@'%'
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%' identified by
'123';
mysql> 3.在从服务器上使用刚才的用户进行测试连接
[root@mysql ~]# mysql -urepl -p'123' -hmysql-master1下面的操作根据如下情况继续
主服务器中有数据
- 如果在启动复制之前有现有数据需要与从属设备同步,请保持客户端正常运行,以便锁定保持不变。这可以防止进行任何进一步的更改,以便复制到从站的数据与主站同步。
- 在主服务器中导出先有的数据
如果主数据库包含现有数据,则必须将此数据复制到每个从站。有多种方法可以实现:
[root@mysql ~]# mysqldump -u用户名 -p密码 --all-databases --master-data=1 > dbdump.db
这里的用户是主服务器的用户如果不使用 --master-data 参数,则需要手动锁定单独会话中的所有表。
- 从主服务器中使用
scp或rsync等工具,把备份出来的数据传输到从服务器中。
在主服务中执行如下命令
[root@mysql ~]# scp dbdump.db root@mysql-slave1:/root/
这里的 mysql-slave1 需要能被主服务器解析出 IP 地址,或者说可以在主服务器中 ping 通。- 配置从服务器,并重启
在从服务器上编辑其配置文件my.cnf并添加如下内容
// my.cnf 文件
[mysqld]
server-id=2- 导入数据到从服务器,并配置连接到主服务器的相关信息
登录到从服务器上,执行如下操作
/*导入数据*/
mysql> source /root/fulldb.dump在从服务器配置连接到主服务器的相关信息
mysql> CHANGE MASTER TO
MASTER_HOST='mysql-master1', -- 主服务器的主机名(也可以是 IP)
MASTER_USER='repl', -- 连接到主服务器的用户
MASTER_PASSWORD='123'; -- 到主服务器的密码启动从服务器的复制线程
mysql> start slave; Query OK, 0 rows affected (0.09 sec)
检查是否成功
在从服务上执行如下操作,加长从服务器端 IO线程和 SQL 线程是否是 OK
mysql> show slave status\G输出结果中应该看到 I/O 线程和 SQL 线程都是 YES, 就表示成功。
执行此过程后,在主服务上操作的修改数据的操作都会在从服务器中执行一遍,这样就保证了数据的一致性。
主服务器中无数据
主服务器中设置
my.cnf配置文件
[mysqld]
log-bin=/var/log/mysql/mysql-bin
server-id=1创建日志目录并赋予权限
[root@mysql ~]# mkdir /var/log/mysql
[root@mysql ~]# chown mysql.mysql /var/log/mysql重启服务
从服务器设置
my.cnf配置文件
[mysqld]
server-id=3重启服务
- 查看主服务器的二进制日志的名称
通过使用命令行客户端连接到主服务器来启动主服务器上的会话,并通过执行以下 FLUSH TABLES WITH READ LOCK 语句来刷新所有表和阻止写语句:
mysql> FLUSH TABLES WITH READ LOCK;
mysql> show master status \G
****************** 1. row ****************
File: mysql-bin.000001
Position: 0
Binlog_Do_DB:
Binlog_Ignore_DB:
Executed_Gtid_Set:
1 row in set (0.00 sec)- 在从服务器的 mysql 中执行如下语句
mysql> CHANGE MASTER TO
MASTER_HOST='mysql-master1',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_LOG_FILE='mysql-bin.000001',
MASTER_LOG_POS=0;
mysql> start slave;
查看
在master上执行show binlog events命令,可以看到第一个binlog文件的内容。
mysql> show binlog events\G
*************************** 1. row ***************************
Log_name: mysql-bin.000001
Pos: 4
Event_type: Format_desc
Server_id: 1
End_log_pos: 107
Info: Server ver: 5.5.28-0ubuntu0.12.10.2-log, Binlog ver: 4
*************************** 2. row ***************************
Log_name: mysql-bin.000001
Pos: 107
Event_type: Query
Server_id: 1
End_log_pos: 181
Info: create user rep
*************************** 3. row ***************************
Log_name: mysql-bin.000001
Pos: 181
Event_type: Query
Server_id: 1
End_log_pos: 316
Info: grant replication slave on *.* to rep identified by '123456'
3 rows in set (0.00 sec)
Log_name 是二进制日志文件的名称,一个事件不能横跨两个文件
Pos 这是该事件在文件中的开始位置
Event_type 事件的类型,事件类型是给slave传递信息的基本方法,每个新的binlog都以Format_desc类型开始,以Rotate类型结束
Server_id 创建该事件的服务器id
End_log_pos 该事件的结束位置,也是下一个事件的开始位置,因此事件范围为Pos~End_log_pos - 1
Info 事件信息的可读文本,不同的事件有不同的信息
在从站上暂停复制
您可以使用STOP SLAVE和 START SLAVE语句停止并启动从站上的复制 。
要停止从主服务器处理二进制日志,请使用 STOP SLAVE:
mysql> STOP SLAVE;当复制停止时,从I / O线程停止从主二进制日志读取事件并将它们写入中继日志,并且SQL线程停止从中继日志读取事件并执行它们。您可以通过指定线程类型单独暂停I / O或SQL线程:
mysql> STOP SLAVE IO_THREAD;
mysql> STOP SLAVE SQL_THREAD;要再次开始执行,请使用以下START SLAVE语句:
mysql> START SLAVE;要启动特定线程,请指定线程类型:
mysql> START SLAVE IO_THREAD;
mysql> START SLAVE SQL_THREAD;复制原理实现细节(了解)
MySQL复制功能使用三个线程实现,一个在主服务器上,两个在从服务器上:
Binlog转储线程 主设备创建一个线程,以便在从设备连接时将二进制日志内容发送到从设备。可以SHOW PROCESSLIST在主服务器的输出中将此线程标识为Binlog Dump线程。
二进制日志转储线程获取主机二进制日志上的锁,用于读取要发送到从机的每个事件。一旦读取了事件,即使在事件发送到从站之前,锁也会被释放。
从属 I/O线程 在从属服务器上发出 START SLAVE 语句时,从属服务器会创建一个 I/O 线程,该线程连接到主服务器并要求主服务器发送其在二进制日志中的更新记录。
从属 I/O线程读取主Binlog Dump线程发送的更新 (请参阅上一项)并将它们复制到包含从属中继日志的本地文件。
此线程的状态显示为 Slave_IO_running输出 SHOW SLAVE STATUS或 Slave_running输出中的状态SHOW STATUS。
从属SQL线程 从属设备创建一个SQL线程来读取由从属 I/O 线程写入的中继日志,并执行其中包含的事件。
当从属服务器从放的事件,追干上主服务器的事件后,从属服务器的 I/O 线程将会处于休眠状态,直到主服务器的事件有更新时,被主服务器发送的信号唤醒。
在前面的描述中,每个主/从连接有三个线程。具有多个从站的主站为每个当前连接的从站创建一个二进制日志转储线程,每个从站都有自己的I / O和SQL线程。
从站使用两个线程将读取更新与主站分开并将它们执行到独立任务中。因此,如果语句执行缓慢,则不会减慢读取语句的任务。例如,如果从服务器尚未运行一段时间,则当从服务器启动时,其I / O线程可以快速从主服务器获取所有二进制日志内容,即使SQL线程远远落后。如果从服务器在SQL线程执行了所有获取的语句之前停止,则I / O线程至少已获取所有内容,以便语句的安全副本本地存储在从属的中继日志中,准备在下次执行时执行奴隶开始。
配置Replication(gtid方式)
基于事务的Replication,就是利用GTID来实现的复制
GTID(全局事务标示符)最初由google实现,在MySQL 5.6中引入.GTID在事务提交时生成,由UUID和事务ID组成.uuid会在第一次启动MySQL时生成,保存在数据目录下的auto .cnf文件里,事务ID则从1开始自增使用GTID的好处主要有两点:
- 不再需要指定传统复制中的master_log_files和master_log_pos,使主从复制更简单可靠
- 可以实现基于库的多线程复制,减小主从复制的延迟
实验环境要求: 5.7.6 以上版本
主库配置
[mysqld]
log-bin=/var/log/mysql/mysql-bin
server-id=1
gtid_mode=ON
enforce_gtid_consistency=1 # 强制执行GTID一致性。重启服务
其他和之前的一样
- 创建专属用户并授权
- 假如有数据导出数据
mysql> CREATE USER 'repl'@'%' IDENTIFIED BY '123';
mysql> GRANT REPLICATION SLAVE ON *.* TO 'repl'@'%';
mysql> 从库配置
测试用户有效性
mysql -urepl -p'123' -hmysql-master1[mysqld]
server-id=2
gtid_mode=ON
enforce_gtid_consistency=1
# 可选项, 把连接到 master 的信息存到数据库中的表中
master-info-repository=TABLE
relay-log-info-repository=TABLE重启服务
假如有数据,先导入数据
mysql> source dump.dbMysql 终端执行连接信息
mysql> CHANGE MASTER TO
MASTER_HOST='172.16.153.10',
MASTER_USER='repl',
MASTER_PASSWORD='123',
MASTER_AUTO_POSITION=1;
> start slave;Replication故障排除
开启 GTID 后的导出导入数据的注意点
Warning: A partial dump from a server that has GTIDs will by default include the GTIDs of all transactions, even those that changed suppressed parts of the database. If you don’t want to restore GTIDs, pass –set-gtid-purged=OFF. To make a complete dump, pass –all-databases –triggers –routines –events
意思是: 当前数据库实例中开启了 GTID 功能, 在开启有 GTID 功能的数据库实例中, 导出其中任何一个库, 如果没有显示地指定–set-gtid-purged参数, 都会提示这一行信息. 意思是默认情况下, 导出的库中含有 GTID 信息, 如果不想导出包含有 GTID 信息的数据库, 需要显示地添加–set-gtid-purged=OFF参数.
mysqldump -uroot -p --set-gtid-purged=OFF --all-databases > alldb.db导入数据是就可以相往常一样导入了。
UUID一致,导致主从复制I/O线程不是yes
Fatal error: The slave I/O thread stops because master and slave have equal MySQL server UUIDs; these UUIDs must be different for replication to work
致命错误:由于master和slave具有相同的mysql服务器uuid,从I/O线程将停止;这些uuid必须不同才能使复制工作。
问题提示主从使用了相同的server UUID,一个个的检查:
检查主从server_id
主库:
mysql> show variables like ‘server_id’;
+—————+——-+
| Variable_name | Value |
+—————+——-+
| server_id | 1 |
+—————+——-+
1 row in set (0.01 sec)
从库:
mysql> show variables like ‘server_id’;
+—————+——-+
| Variable_name | Value |
+—————+——-+
| server_id | 2 |
+—————+——-+
1 row in set (0.01 sec)
server_id不一样,排除。
检查主从状态:
主库:
mysql> show master status;
+——————+———-+————–+——————+——————-+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+——————+———-+————–+——————+——————-+
| mysql-bin.000001 | 154 | | | |
+——————+———-+————–+——————+——————-+
1 row in set (0.00 sec)
从库:
mysql> show master status;
+——————+———-+————–+——————+——————-+
| File | Position | Binlog_Do_DB | Binlog_Ignore_DB | Executed_Gtid_Set |
+——————+———-+————–+——————+——————-+
| mysql-bin.000001 | 306 | | | |
+——————+———-+————–+——————+——————-+
1 row in set (0.00 sec)
File一样,排除。
最后检查发现他们的auto.cnf中的server-uuid是一样的。。。
[root@localhost ~]# vim /var/lib/mysql/auto.cnf
[auto]
server-uuid=4f37a731-9b79-11e8-8013-000c29f0700f
修改uuid并重启服务
数据库中间MyCAT读写分离实现 (重要!!!)
Mycat 是一个开源的分布式数据库系统,但是由于真正的数据库需要存储引擎,而 Mycat 并没有存 储引擎,所以并不是完全意义的分布式数据库系统。 那么 Mycat 是什么?Mycat 是数据库中间件,就是介于数据库与应用之间,进行数据处理与交互的中间服 务。
MyCAT 是使用 JAVA 语言进行编写开发,使用前需要先安装 JAVA 运行环境(JRE),由于 MyCAT 中使用了 JDK7 中的一些特性,所以要求必须在 JDK7 以上的版本上运行。
部署环境
1下载JDK
[root@mycat ~]# wget --no-cookies \
--no-check-certificate \
--header \
"Cookie: oraclelicense=accept-securebackup-cookie" \
http://download.oracle.com/otn-pub/java/jdk/8u181-\
b13/96a7b8442fe848ef90c96a2fad6ed6d1/jdk-8u181-linux-\
x64.tar.gz
// --no-check-certificate 表示不校验SSL证书,因为中间的两个302会访问https,会涉及到证书的问题,不校验能快一点,影响不大.2.解压文件
[root@mycat ~]# tar -xf jdk-8u181-linux-x64.tar.gz -C /usr/local/
[root@mycat ~]# ln -s /usr/local/jdk1.8.0_181/ /usr/local/java3.配置环境变量
[root@mycat ~]# vim /etc/profile.d/java.sh
export JAVA_HOME=/usr/local/java
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
使环境变量生效
[root@mycat ~]# source /etc/profile.d/java.sh部署Mycat
下载
[root@mycat ~]# wget http://dl.mycat.io/1.6.5/Mycat-server-1.6.5-release-20180122220033-linux.tar.gz
解压
[root@mycat ~]# tar xf Mycat-server-1.6.5-release-20180122220033-linux.tar.gz -C /usr/local/
配置Mycat
认识配置文件
MyCAT 目前主要通过配置文件的方式来定义逻辑库和相关配置:
/usr/local/mycat/conf/server.xml 定义用户以及系统相关变量,如端口等。其中用户信息是前端应用程序连接 mycat 的用户信息。
/usr/local/mycat/conf/schema.xml 定义逻辑库,表、分片节点等内容。
配置 server.xml
以下为代码片段
下面的用户和密码是应用程序连接到 MyCat 使用的,可以自定义配置
而其中的schemas 配置项所对应的值是逻辑数据库的名字,也可以自定义,但是这个名字需要和后面 schema.xml 文件中配置的一致。
vim server.xml
<!--下面的用户和密码是应用程序连接到 MyCat 使用的.schemas 配置项所对应的值是逻辑数据库的名字,这个名字需要和后面 schema.xml 文件中配置的一致。-->
<user name="mycatdb" defaultAccount="true">
<property name="password">1</property>
<property name="schemas">mycat_db</property>
<!-- 表级 DML 权限设置 -->
<!--
<privileges check="false">
<schema name="TESTDB" dml="0110" >
<table name="tb01" dml="0000"></table>
<table name="tb02" dml="1111"></table>
</schema>
</privileges>
-->
</user>
<!--下面是另一个用户,并且设置的访问 TESTED 逻辑数据库的权限是 只读
<user name="mycatuser">
<property name="password">123</property>
<property name="schemas">mycat_db</property>
<property name="readOnly">true</property>
</user>
-->
</mycat:server>
== 上面的配置中,假如配置了用户访问的逻辑库,那么必须在 schema.xml 文件中也配置这个逻辑库,否则报错,启动 mycat 失败 ==
配置schema.xml
以下是配置文件中的每个部分的配置块儿
逻辑库和分表设置
<schema name="mycat_db" // 逻辑库名称,与server.xml的一致
checkSQLschema="false" // 不检查
sqlMaxLimit="100" // 最大连接数
dataNode="tiger1"> // 数据节点名称
<!--这里定义的是分表的信息-->
</schema>
数据节点
<dataNode name="tiger1" // 此数据节点的名称
dataHost="localhost1" // 主机组
database="mycat_test" /> // 真实的数据库名称主机组
<dataHost name="localhost1" // 主机组
maxCon="1000" minCon="10" // 连接
balance="0" // 负载均衡
writeType="0" // 写模式配置
dbType="mysql" dbDriver="native" // 数据库配置
switchType="1" slaveThreshold="100">
<!--这里可以配置关于这个主机组的成员信息,和针对这些主机的健康检查语句-->
</dataHost>balance 属性
负载均衡类型,目前的取值有 3 种:
1. balance="0", 不开启读写分离机制,所有读操作都发送到当前可用的 writeHost 上。
2. balance="1", 全部的 readHost 与 stand by writeHost 参与 select 语句的负载均衡,简单的说,当双主双从模式(M1->S1,M2->S2,并且 M1 与 M2
互为主备),正常情况下,M2,S1,S2 都参与 select 语句的负载均衡。
4. balance="2", 所有读操作都随机的在 writeHost、readhost 上分发。
5. balance="3", 所有读请求随机的分发到 wiriterHost 对应的 readhost 执行,writerHost 不负担读压力,注意 balance=3 只在 1.4 及其以后版本有,1.3 没有。
writeType 属性
负载均衡类型,目前的取值有 3 种:
1. writeType="0", 所有写操作发送到配置的第一个 writeHost,第一个挂了切到还生存的第二个writeHost,重新启动后已切换后的为准.
2. writeType="1",所有写操作都随机的发送到配置的 writeHost,1.5 以后废弃不推荐。健康检查
<heartbeat>select user()</heartbeat>读写配置
<writeHost host="hostM1" url="192.168.19.176:3306" user="root" password="1">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="192.168.19.177:3306" user="root" password="1" />
</writeHost>以下是组合为完整的配置文件,适用于一主一从的架构
<?xml version="1.0"?>
<!DOCTYPE mycat:schema SYSTEM "schema.dtd">
<mycat:schema xmlns:mycat="http://io.mycat/">
<schema name="mycat_db"
checkSQLschema="false"
sqlMaxLimit="100"
dataNode="tiger1">
<!--这里定义的是分库分表的信息-->
</schema>
<dataNode name="tiger1"
dataHost="localhost1" database="mycat_test" />
<dataHost name="localhost1"
maxCon="1000" minCon="10"
balance="0"
writeType="0"
dbType="mysql" dbDriver="native"
switchType="1" slaveThreshold="100">
<heartbeat>select user()</heartbeat>
<!-- can have multi write hosts -->
<writeHost host="hostM1" url="192.168.19.176:3306"
user="root" password="1">
<!-- can have multi read hosts -->
<readHost host="hostS2" url="192.168.19.177:3306"
user="root" password="1" />
</writeHost>
</dataHost>
</mycat:schema>启动 mycat
[root@mycat ~]# /usr/local/mycat/bin/mycat start
支持一下参数
start | restart |stop | status在真实的 master 数据库上给用户授权
mysql> grant all on mycat_test.* to root@'%' identified by '1';
mysql> flush privileges;测试
在 mycat 的机器上测试用户权限有效性
测试是否能正常登录上 主服务器
mysql -uroot -p'123' -h192.168.19.176继续测试是否能登录上从服务器
mysql -uroot -p'123' -h192.168.19.177通过客户端进行测试是否能登录到 mycat 上
192.168.19.178 是 mycat 的主机地址
注意端口号是 8066
[root@mysqlclient ~]# mysql -umycatdb -p1 -h192.168.19.178 -P8066
MySQL [(none)]> show databases;
+----------+
| DATABASE |
+----------+
| mycat_db |
+----------+
1 row in set (0.00 sec)继续测试读写分离策略
使用 mysql 客户端工具使用 mycat 的账户和密码登录 mycat ,
之后执行 select 语句。
之后查询 mycat 主机上 mycat 安装目录下的 logs/mycat.log 日志。
在日志重搜索查询的语句或者查询 从库的 ip 地址,应该能搜索到



